
Trong bài viết này mình sẽ giới thiệu chi tiết về cách tạo một project với Scrapy và sử dụng để phân tích lấy dữ liệu nhà đất từ trang alonhadat. Nếu máy bạn chưa có Scrapy thì có thể cài đặt bằng pip, xem chi tiết tại website https://pypi.org/project/Scrapy/.
Nếu bạn quan tâm tới một luồng dữ liệu đầy đủ từ việc
crawl data->làm sạch->phân tích và trực quan hóa->học máy->website demothì có thể tham khảo repo https://github.com/trannguyenhan/house-price-prediction
Tạo một project Scrapy
Tạo một project Scrapy với câu lệnh:
1
scrapy startproject crawlerdata
Tạo một spider alonhadat bằng câu lệnh:
1
scrapy genspider alonhadat alonhadat.com.vn
Định nghĩa dữ liệu cần lấy về
Định nghĩa rõ ràng các trường cần lấy về trong file items.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import scrapy
class DataPriceItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
area = scrapy.Field() # dien_tich \ double
address = scrapy.Field() # dia_chi \ string
description = scrapy.Field() # mo_ta \ string
floor_number = scrapy.Field() # so_lau (so_tang) \ int
bedroom_number = scrapy.Field() # so_phong_ngu \ int
is_dinning_room = scrapy.Field() # co_phong_an? \ boolean
is_kitchen = scrapy.Field() # co_bep? \ boolean
is_terrace = scrapy.Field() # co_san_thuong? \ boolean
is_car_pack = scrapy.Field() # co_cho_de_xe_hoi? \ boolean
is_owner = scrapy.Field() # chinh_chu? \ boolean
start_date = scrapy.Field() # ngay_dang_tin \ date || string
end_date = scrapy.Field() # ngay_ket_thuc \ date || string
type = scrapy.Field() # in('nha_mat_tien', 'nha_trong_hem') \ string
direction = scrapy.Field() # phuong_huong_nha (nam, bac, dong, tay) \ string
street_in_front_of_house = scrapy.Field() # do_rong_duong_truoc_nha \ int
width = scrapy.Field() # chieu_dai \ string
height = scrapy.Field() # chieu_rong \ string
law = scrapy.Field() # phap_ly \ string
price = scrapy.Field() # gia_nha \ double
Vì crawl data chỉ là bước đầu trong cả một luồng dữ liệu của chúng ta nên cần command để ghi lại rõ ràng các trường tránh nhầm lẫn về sau và cũng để sau nhìn lại sẽ dễ dàng hiểu và tiếp cận project hơn.
Với project đơn giản đầu tiên này thì chưa cần quan tâm tới các file middlelwares.py hay pipelines.py. Code trong các file này tạm thời để mặc định.
Chỉnh sửa file settings.py
Chỉnh sửa lại file settings.py:
1
2
3
4
5
6
7
8
9
10
11
12
BOT_NAME = 'data_price'
SPIDER_MODULES = ['data_price.spiders']
NEWSPIDER_MODULE = 'data_price.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:48.0) Gecko/20100101 Firefox/48.0',
}
FEED_EXPORT_ENCODING = 'utf-8'
Nếu chương trình Scrapy của bạn mới tạo có biến ROBOTSTXT = False thì hãy gán lại nó bằng True nha, lý do cụ thể thì có thể xem lại bài viết trước của mình https://demanejar.github.io/posts/what-is-crawler-and-something/#s%E1%BB%AD-d%E1%BB%A5ng-file-robotstxt
Viết Spider phân tích HTML website
Trong AlonhadatSpider chúng ta sẽ cần phải viết 3 hàm: start_requests, parse_link, parse.
hàm start_requests
Hàm này là hàm sẽ được chạy đầu tiên và chúng sẽ có nhiệm vụ khởi tạo các link cần crawl. Nói thế này hơi khó hiểu, ví dụ này đi, ví dụ bạn cần crawl trang alonhadat từ trang 3501 tới trng 4501 thì trước hết là cần phải phân tích xem website này các url được thiết kế thế nào. Vào website xem thử 1 số trang:
1
2
3
https://alonhadat.com.vn/nha-dat/can-ban.html
https://alonhadat.com.vn/nha-dat/can-ban/trang--2.html
https://alonhadat.com.vn/nha-dat/can-ban/trang--3.html
Từ trên tạm kết luận là url của website nay giữa các page 1,2 sẽ dạng ../trang--i.html, từ suy đoán đó thì chúng ta viết hàm start_requests:
1
2
3
4
5
6
7
8
def start_requests(self):
pages = []
for i in range(3501,4501):
domain = 'https://alonhadat.com.vn/can-ban-nha/trang--{}.htm'.format(i)
pages.append(domain)
for page in pages:
yield scrapy.Request(url=page, callback=self.parse_link)
Vậy là đã khởi tạo xong các link cần crawl, giờ mỗi link được tạo sẽ là đầu vào cho hàm parse_link.
Hàm parse_link
Nhiệm vụ của hàm này là lấy toàn bộ các link bài viết ở trong từng trang listing bài viết được tạo ở hàm start_requests, ví dụ khi vào một trang lising bài viết như sau:
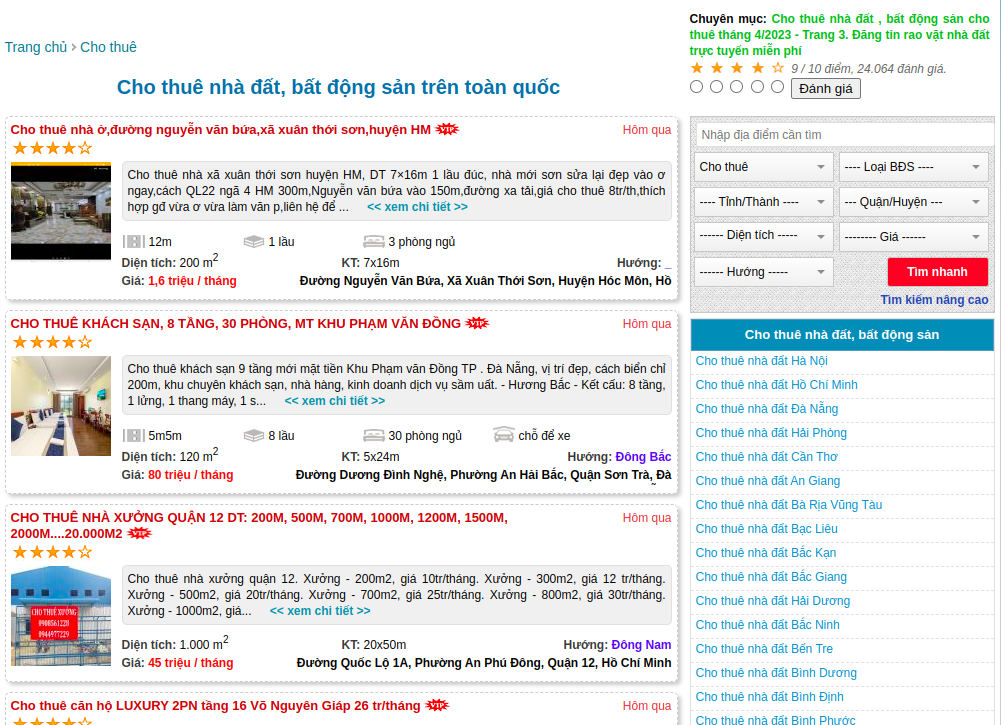
Kết quả cần đạt được là list các link bài viết kia:
1
2
3
4
5
[
'https://alonhadat.com.vn/cho-thue-nha-o-duong-nguyen-van-bua-xa-xuan-thoi-son-huyen-hm-12662015.html',
'https://alonhadat.com.vn/cho-thue-khach-san-8-tang-30phong-mt-khu-pham-van-dong-12682000.html',
...
]
Chuột phải vào element cần lấy xpath hoặc css selector (với xpath hay css selector thì cũng giống nhau thôi, mình thì thích dùng css selector hơn nên từ giờ mình sẽ chủ yếu đề cập tới css selector) để lấy css selector của phần từ:
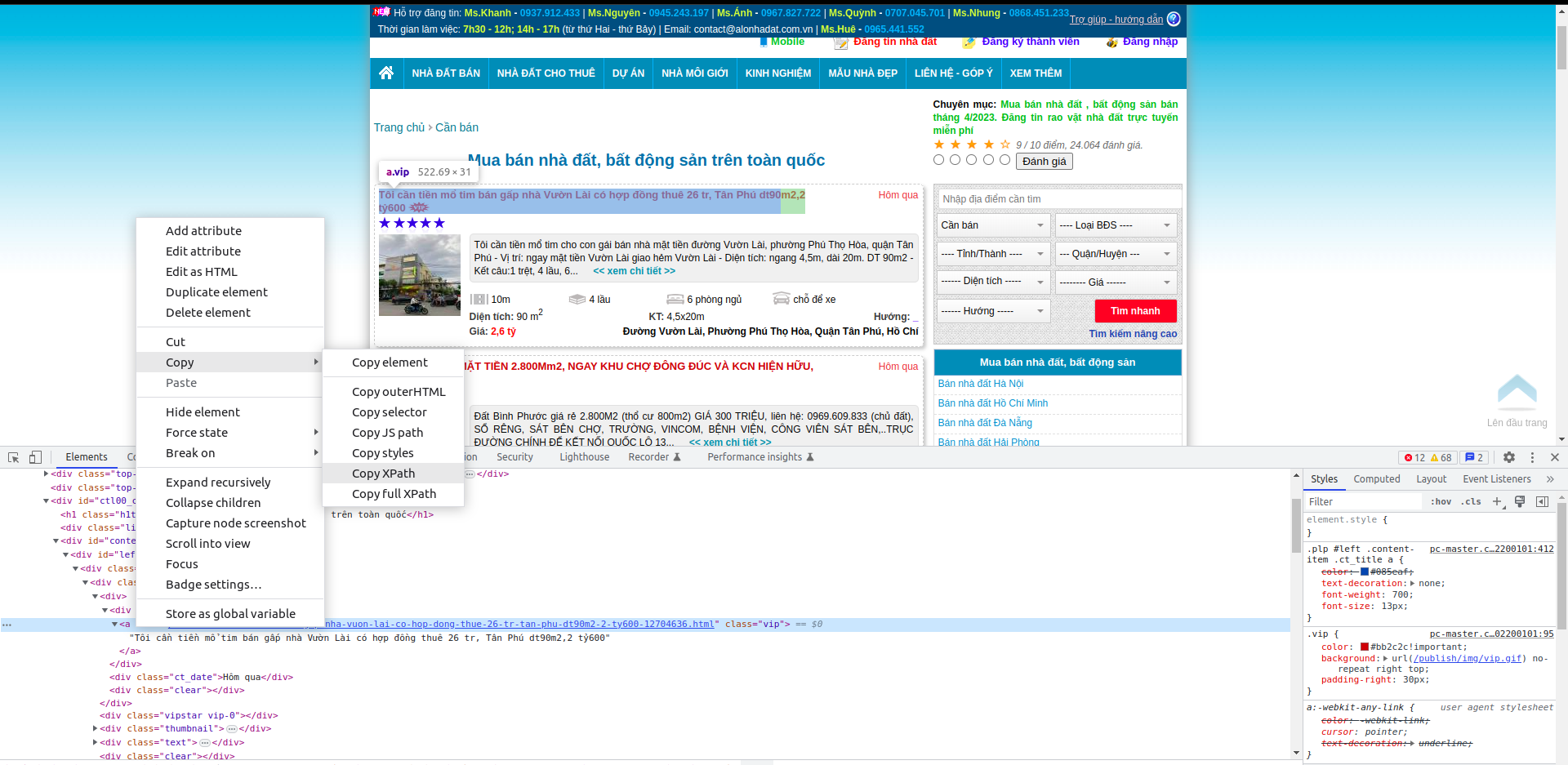
Với trường hợp này, thì css selector của phần tử chứa url bài viết đầu tiên là (là 1 element tag a):
1
#left > div.content-items > div:nth-child(1) > div:nth-child(1) > div.ct_title > a
Trong Scrapy để lấy thêm thuộc tính thì chúng ta thêm ::attr(href) với href là thuộc tính của element đó, vậy để lấy được url chứa trong thuôc tính href của tag a thì css selector sẽ thêm như sau:
1
#left > div.content-items > div:nth-child(1) > div:nth-child(1) > div.ct_title > a::attr(href)
Lưu ý: tiện đây mình cũng lưu ý luôn về việc lấy
CSS SELECTORkiểu này. Đầu tiên là nó rất dễ thay đổi, tiếp là lấy kiểu này bạn sẽ chỉ lấy được của một phần từ bạn cần lấy, trong các bài viết sau mình sẽ hướng dẫn mọi người các lấycss selectorcủa từng phần từ bằng việc phân tích các thuộc tính độc nhất của phần từ đó hoặc các phần tử liền kề, còn với bài viết này chúng ta sẽ đi tiếp với cách này.
Đây mới là css selector của url bài viết đầu tiên, các url bài viết tiếp theo thì sau, chúng ta làm tương tự như vậy sẽ có một danh sách css selector chứa các url bài viết như sau:
1
2
3
4
#left > div.content-items > div:nth-child(1) > div:nth-child(1) > div.ct_title > a::attr(href)
#left > div.content-items > div:nth-child(2) > div:nth-child(1) > div.ct_title > a::attr(href)
#left > div.content-items > div:nth-child(3) > div:nth-child(1) > div.ct_title > a::attr(href)
#left > div.content-items > div:nth-child(4) > div:nth-child(1) > div.ct_title > a::attr(href)
Tạm dự đoán được cấu trúc của css selector chứa link bài viết, chúng ta sẽ viết hàm parse_link như sau:
1
2
3
4
5
6
7
def parse_link(self, response):
for i in range(1, 21):
str = '#left > div.content-items > div:nth-child({}) > div:nth-child(1) > div.ct_title > a::attr(href)'.format(i)
link = response.css(str).extract_first()
link = 'https://alonhadat.com.vn/' + link
yield scrapy.Request(url=link, callback=self.parse)
Tại sao lại là range(1, 21), cũng dựa vào việc phân tích website thì sẽ thấy một trang listing bài viết sẽ có 21 bài viết. Bây giờ mỗi url bài viết sẽ là đầu vào cho hàm parse, nhiệm vụ tiếp theo là phân tích và lấy những dữ liệu cần thiết đã được định nghĩa trong class Item.
Hàm parse
Với cách lấy css selector như trên thì chúng ta cũng viết nhanh được hàm parse như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def parse(self, response, **kwargs):
item = DataPriceItem()
item['price'] = self.extract(response, '#left > div.property > div.moreinfor > span.price > span.value')
item['description'] = self.extract(response, '#left > div.property > div.detail.text-content')
item['address'] = self.extract(response, '#left > div.property > div.address > span.value')
item['area'] = self.extract(response, '#left > div.property > div.moreinfor > span.square > span.value')
item['start_date'] = self.extract(response, '#left > div.property > div.title > span', 'start_date')
item['end_date'] = None
result_table = self.extract_table(response.css('table').get())
item['floor_number'] = result_table[0]
item['bedroom_number'] = result_table[1]
item['is_dinning_room'] = result_table[2]
item['is_kitchen'] = result_table[3]
item['is_terrace'] = result_table[4]
item['is_car_pack'] = result_table[5]
item['is_owner'] = result_table[6]
item['type'] = result_table[7]
item['direction'] = result_table[8]
item['street_in_front_of_house'] = result_table[9]
item['width'] = result_table[10]
item['height'] = result_table[11]
item['law'] = result_table[12]
yield item
Ở hàm này chúng ta phải khai báo một DataPriceItem và trả về đối tượng đó để luồng của Scrapy được chạy thông suốt. Với hàm extract hay extract_table là các hàm viết thêm để tái sử dụng lại code.
Để xem code chi tiết của project bạn có thể xem tại repo project của Demanejar: https://github.com/demanejar/crawl-alonhadat.
Trong dự án mình còn sử dụng thêm 1 thư viện BeautifulSoup đê phân tích mã HTML (được sử dụng trong hàm extract_table, bạn có thể vào trong repo qua github để xem chi tiết). BeautifulSoup cũng là một thư viện khá nổi tiếng để lấy và phân tích thông tin từ website, tuy nhiên thì với mình thì BeautifulSoup mạnh hơn ở phương diện phân tích mã HTML và mình cũng hay sử dụng BeautifulSoup trong Scrapy để phân tích một số đoạn mã HTML.
Chạy Scrapy
Cuối cùng sau khi viết xong thì chạy project để lấy dữ liệu thôi, chạy command:
1
scrapy crawl alonhadat -o ../data/output.json --set FEED_EXPORT_ENCODING=utf-8
Dữ liệu thô crawl về bạn có thể tham khảo tại: https://github.com/trannguyenhan/house-price-prediction/tree/master/data.
Hiện tại thì alonhadat đang có một số biện pháp để tránh bị crawl, với bài viết này mình cũng chưa đề cập tới việc làm sao để vượt được sự ngăn chặn này của alonhadat, mình sẽ đề cập thêm ở các bài viết sau trong series này. Với bài viết này chỉ là cách phân tích và lấy dữ liệu của website. Với các repo được đề cập tới trong bài viết, nếu các bạn thấy hữu ích có thể cho các repo 1 star nha, cảm ơn mọi người! Bài viết này mình cũng kết thúc ở đây thôi.
Vì website không có mục bình luận dưới bài viết nên mọi người thảo luận và góp ý cho mình tại GITHUB DISCUSSION này nha: https://github.com/orgs/demanejar/discussions/1.