
Proxy chắc là khái niệm đã không còn xa lạ gì với tất cả mọi người. Với người làm về crawl dữ liệu thì proxy như vật bất ly thân. Trong bài viết này, mình sẽ hướng dẫn cách cấu hình proxy cho project Scrapy. Project mình sử dụng để làm ví dụ cho bài viết này là project crawl alonhadat https://github.com/demanejar/crawl-alonhadat.
Với mỗi bài viết của mình như bài viết này là “Cấu hình proxy cho project Scrapy”, nhưng mình đang không muốn chỉ nói về cấu hình proxy trong project như nào, mình muốn nói rộng hơn ra một tí về những vấn đề liên quan. Nếu bạn quan tâm tới ý chính là cấu hình proxy cho project Scrapy như nào thì có thể bỏ qua phần dạo đầu này và kéo mạnh tay hơn một tí xuống tới đoạn sau của bài viết.
Proxy và các website chặn bot dựa trên lưu lượng truy cập bất thường
Bài viết trước chúng ta đã đi phân tích website, viết chương trình để thu thập dữ liệu. Tuy nhiên thì như thế là chưa đủ, bây giờ thì alonhadat đã thực hiện ban các IP mà có lưu lượng truy cập nhiều trong khoảng thời gian nhất định. Dễ thấy nhất thì chỉ cần chạy project trên tầm 4-5 phút (hoặc ít hơn là 2-3 phút thôi) sẽ thấy sinh ra một tá exception và sau khi truy cập lại website alonhadat sẽ có kết quả:
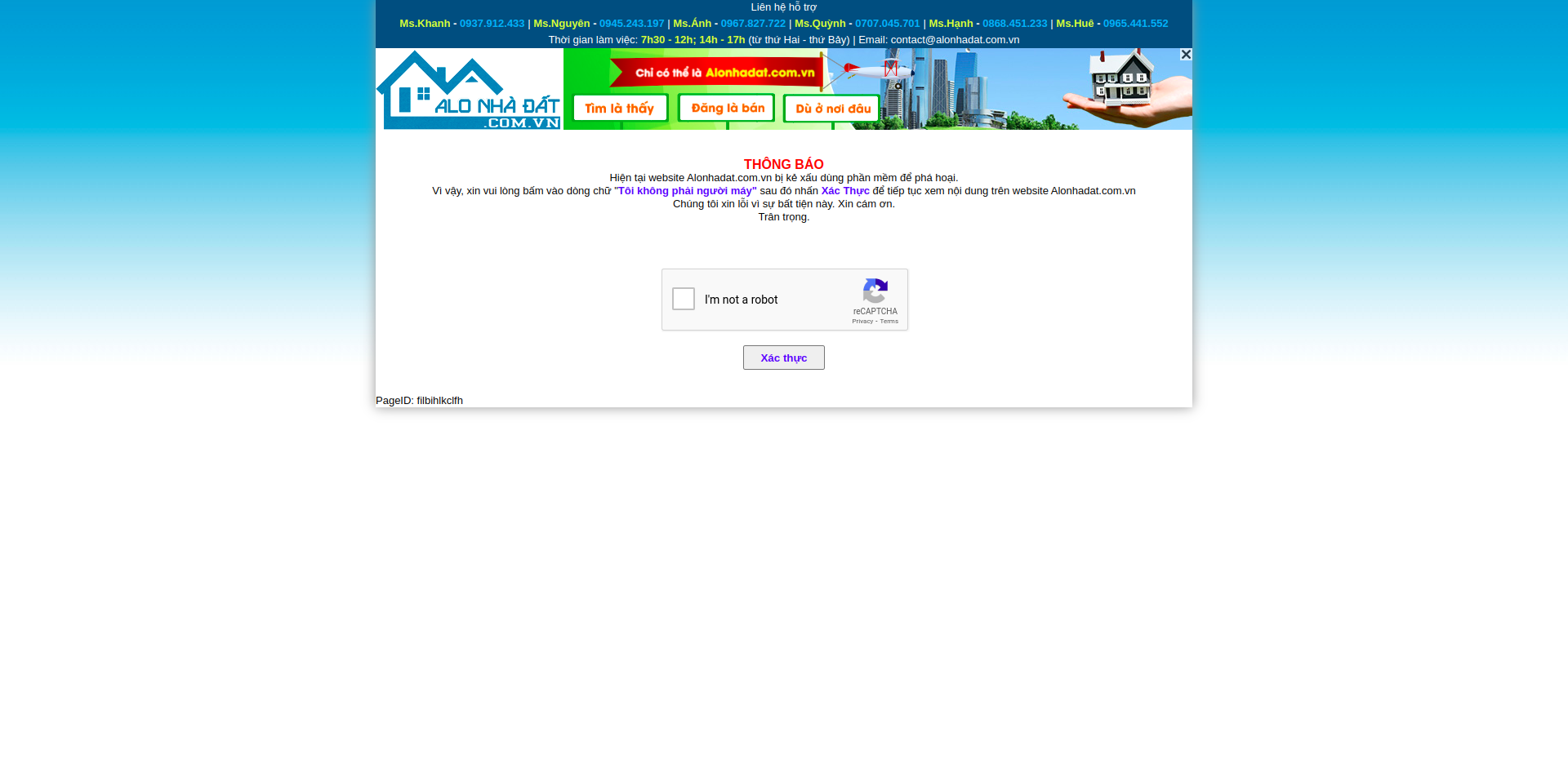
Với hình ảnh này có thể tạm dự đoán là alonhadat đang chặn bot theo IP, vì ngoài các bot bị bắt vươt capcha thì khi người dùng thật vào trang web cũng đang bị bắt vượt capcha. Cách này là một trong những cách đơn giản nhất để bảo vệ website khỏi các con bot crawl, cứ thấy IP nào có lưu lượng truy cập bất thường là ban luôn, 1-2 ngày sau hay 1-2 tháng sau thì lại bỏ, bất thường lai ban tiếp.
Với những website sử dụng cách ban này thì cơ bản sẽ có 2 cách để tránh:
1 là dùng proxy, thật nhiều proxy. Phải tùy theo website chặn như nào, nếu như cái ngưỡng chặn của website là nhỏ (ngưỡng ở đây mình đang muốn nói tới là số lượt truy cập website trên một thời gian nhất định) thì chúng ta sẽ phải cần thật nhiều proxy, còn nếu ngưỡng này cao hơn thì chúng ta có thể sẽ cần ít proxy hơn. Còn việc cần bao nhiêu proxy là đủ thì phải qua thử nghiệm. Ví dụ như trước mình crawl website https://www.yelp.com/, mình sử dụng 1 pool có 10 proxy, mỗi request để cách nhau là 2s và mỗi request sẽ pick random 1 proxy để truy cập vào website thì sau 2-3 tiếng thì 10 proxy đã bị ban sạch, vì thế mình quyết định tăng lên 100, thời gian lần này lâu hơn là sau 1 đêm 100 proxy này cũng bị ban sạch, vấn đề là giờ cần nhiều proxy hơn nữa, 1000 thì sao? Và đấy mới dừng lại ở dự đoán thôi và vì 1000 proxy thì bao tiền cho đủ nên mình quyết định thôi
2 thì khó hơn đó là viết script để bypass capcha. Cách này không hẳn lúc nào cũng dùng được vì có một số website họ chặn luôn chứ không phải là bắt người dùng vượt capcha để tiếp tục xem nội dung, tiêu biểu như https://www.yelp.com/ và website này tất nhiên là có ngưỡng chặn lớn hơn. Với việc các capcha này rất dễ thay đổi sang loại khác vì vậy các đoán script bạn viết cũng dùng được trong một thời gian khá ngắn, và hiện nay cũng có nhiều các loại capcha rất phức tạp, việc có thể bypass các loại capcha mới này nhìn chung là khó
Với cách ban này cũng mang lại trải nghiệm khá tệ cho người dùng. Khi mình là người đi crawl thì alonhadat đang ban IP của mình và mình vào website đang phải vượt capcha, nhưng các bạn cùng phòng của mình dùng chung một wifi và có chung một IP cũng đang bị bắt vươt capcha như vậy mặc dù họ trả làm gì. Vì thế có thể là website đang sử dụng phương pháp này là tạm thời trong thời trong khi họ nghiên cứu để có phương án tốt hơn.
Data Flow và kiến trúc của Scrapy
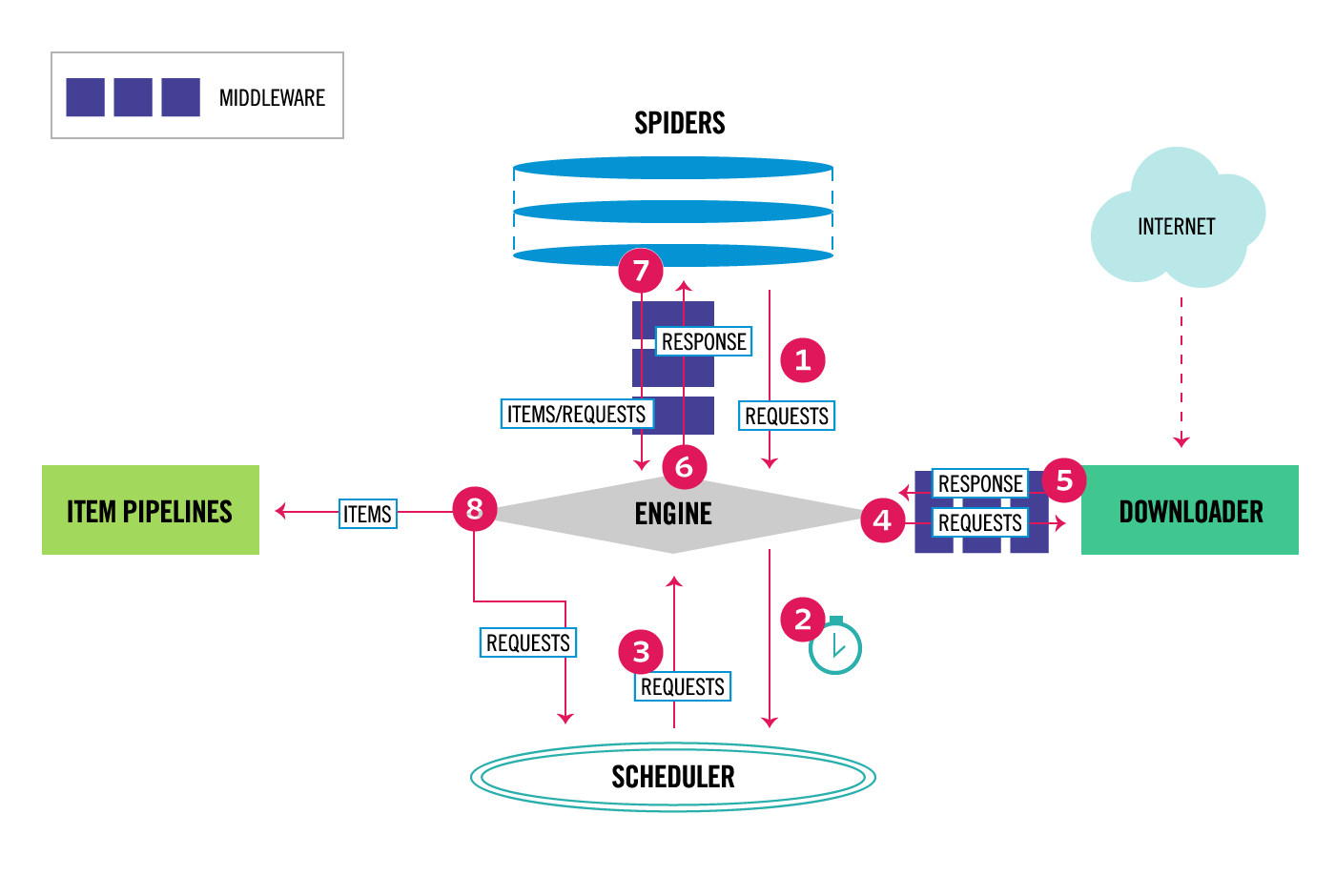
Scrapy sẽ gồm 6 thành phần:
Scrapy Engine: chịu trách nhiệm trong việc điều khiển dòng dữ liệu di chuyển giữa các thành phần trong hệ thống, kích hoạt một số sự kiện trong một số điều kiện nhất định
Downloader: tìm và tải các đoạn mã HTML từ trang web được chỉ định
Spiders: là nơi chúng ta làm việc chủ yếu, nơi viết các đoạn mã để phân tích website
Item Pipeline: chịu trách nhiệm xử lý các Item được trích xuất và tạo bởi Spiders
Middleware: sẽ có 2 loại middleware, 1 là middleware nằm giữa Spiders và Engine, middleware này thường sẽ ít sử dụng hơn vì các đoạn mã được viết trong Spider Middleware cũng có thể thay thế bằng cách viết trong Spiders hoặc Item Pipeline. 2 là Downloader Middleware nằm giữa Downloader và Engine, nó nhằm mục đích xử lý các request trước khi chúng được đưa tới Downloader điển hình nhất như là thêm proxy vào các request
Qua việc tìm hiểu về từng thành phần và chức năng của từng thành phần chắc mọi người đều đã hình dung ra chúng ta sẽ cấu hình proxy cho từng request trong Downloader Middleware.
Cấu hình proxy cho project Scrapy
Nếu bạn chưa biết sử dụng proxy từ website nào thì có thể tham khảo website https://proxy.webshare.io/, proxy trên website này rẻ mà cũng khá chất lượng, mỗi nick còn có 10 proxy free dùng để test.
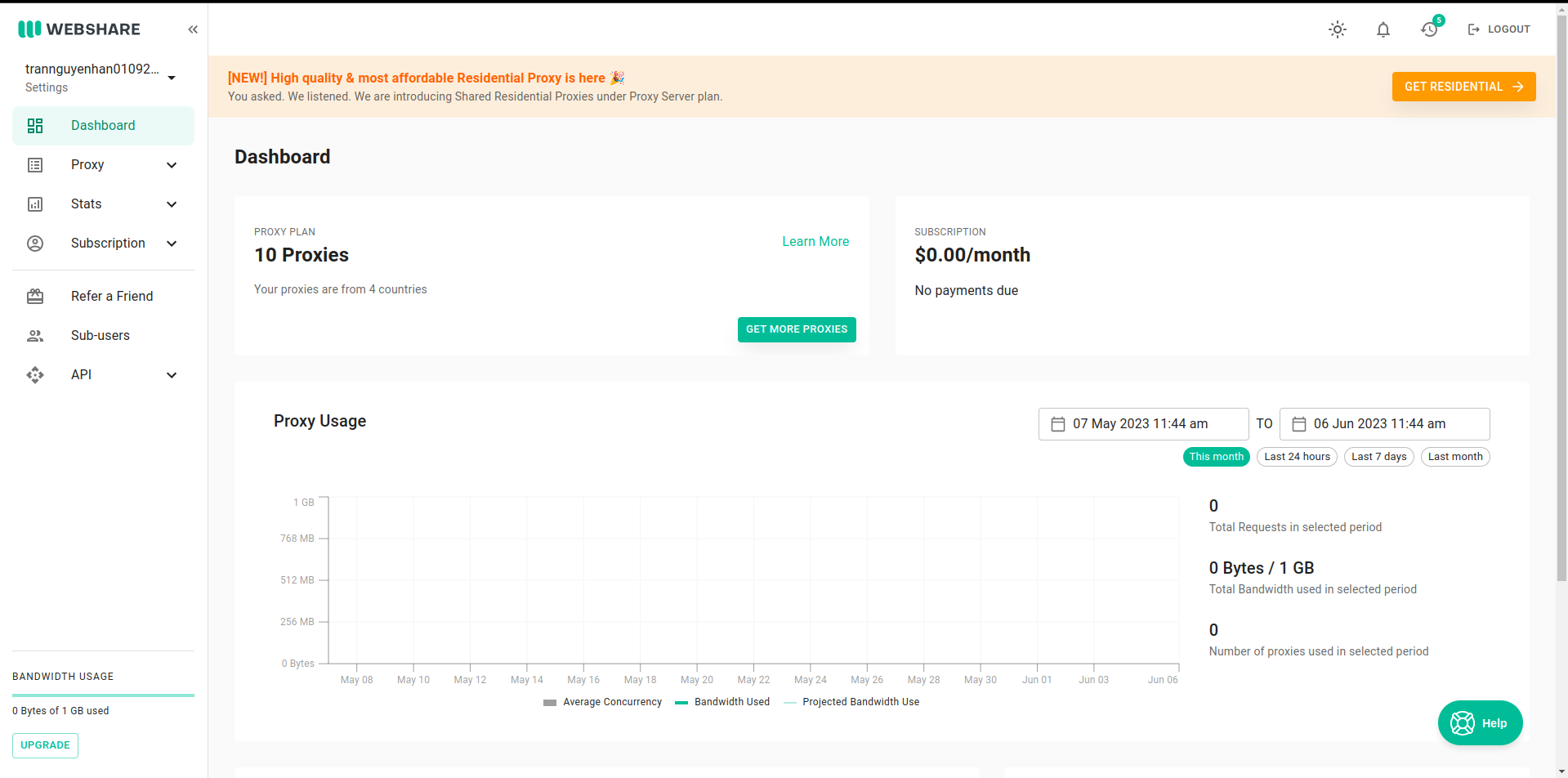
Vào mục Proxy -> List -> Download tải về list proxy, đổi tên file tải về thành proxies.txt và copy chúng vào thư mục project.
Trong file middlewares.py chính là nơi chứa các đoạn code của Spider Middleware và Downloader Middleware. Trong file có 2 class và các method được định nghĩa và comment rõ ràng cách sử dụng.
Để thêm proxy cho các request trước khi được gửi tới Downloader, chúng ta sẽ viết vào hàm process_request của class DataPriceDownloaderMiddleware:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
from w3lib.http import basic_auth_header
import random
proxyPools = open("data_price/proxies.txt", "r").read().split("\n")
class DataPriceDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
proxy = random.choice(proxyPools).split(":")
httpsProxy = proxy[0]
portProxy = proxy[1]
usernameProxy = proxy[2]
passwordProxy = proxy[3]
request.meta['proxy'] = "http://" + httpsProxy + ":" + portProxy
request.headers['Proxy-Authorization'] = basic_auth_header(usernameProxy, passwordProxy)
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
Chúng ta định nghĩa trước một
proxyPoolsđọc từ fileproxies.txtvừa được thêm vào projectTrong
process_requestchúng ta sẽ pick random một proxy bất kì và add chúng vào headers
Bây giờ vào file settings.py tìm tới vị trí DOWNLOADER_MIDDLEWARES và bỏ comment, sau đó thêm vào môt HttpProxyMiddleware nữa để các Middleware này được gọi tới khi bắt đầu crawl:
1
2
3
4
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 600,
'data_price.middlewares.DataPriceDownloaderMiddleware': 543,
}
Chuyển con số của HttpProxyMiddleware lớn hơn DataPriceDownloaderMiddleware để nó được gọi sau. Cái số 543 và 600 là độ ưu tiên để hệ thống biết cần gọi tới cái nào trước.
Giờ chạy lại project chúng ta sẽ lại thấy các kết quả lần lượt được trả về và vừa nãy còn bắn ra rất nhiều exception do các element không được tìm thấy:
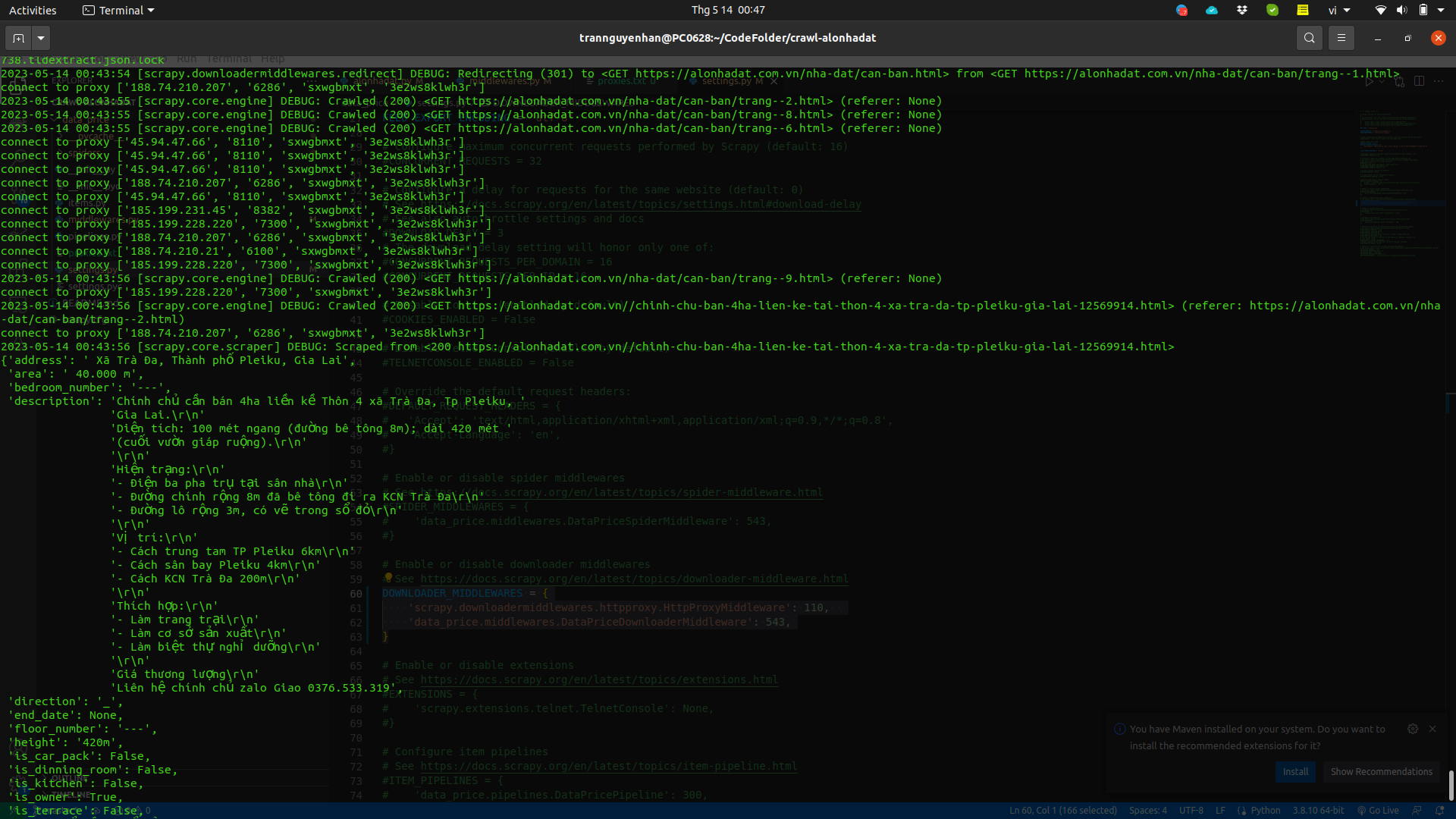
Bạn có thể thêm một proxy pool với nhiều proxy hơn và để thêm thời gian delay trong settings.py tránh việc request được gửi quá nhanh và liên tục:
1
DOWNLOAD_DELAY = 2
Xem chi tiết project tại: https://github.com/demanejar/crawl-alonhadat
Sử dụng thư viện để cấu hình proxy cho project Scrapy
Thư viện mình nói tới ở đây là Rotating proxies.
Cài đặt Rotating proxies:
1
pip install scrapy-rotating-proxies
Thêm biến ROTATING_PROXY_LIST vào file settings.py:
1
2
3
4
ROTATING_PROXY_LIST = [
'host1:port1',
'host2:port2',
]
Hoặc sử dụng ROTATING_PROXY_LIST_PATH để cấu hình tới file proxies:
1
ROTATING_PROXY_LIST_PATH = '/my/path/proxies.txt'
Xem docs chi tiết của thư viện này tại https://github.com/TeamHG-Memex/scrapy-rotating-proxies.
Vì website không có mục bình luận dưới bài viết nên mọi người thảo luận và góp ý cho mình tại GITHUB DISCUSSION này nha: https://github.com/orgs/demanejar/discussions/1.