
Nếu với mỗi website lại viết 1 spider để phân tích thông tin thì sẽ rất mất thời gian, nhất là với các website tin tức, có hàng ngàn các website tin tức khác nhau và chúng còn mọc ra mỗi ngày.
Vậy bây giờ có một bài toán đặt ra là cần phân tích nội dung của 1000 website báo chí, và nhiệm vụ của chúng ta là phải lập lịch crawl 1000 website báo chí này hàng ngày. Việc lập lịch thì chúng ta có thể tạm giải quyết bằng crontab, vậy còn crawl 1000 website thì sao, không thể viết cả 1000 spider để parse từng website được! Vậy bài viết này chúng ta sẽ cùng tìm hiểu thêm cách sử dụng cơ sở dữ liệu để lưu cấu hình, cụ thể trong bài viết này sẽ sử dụng MySQL.
Có thể có nhiều bạn thắc mắc là phân tích nội dung của 1000 website báo chí để làm gì? Bài toán này chủ yếu là để phân tích trend, từ khóa, sự kiện hot theo từng ngày, phân tích các nội dung, cho biết trang nào hay đăng lại bài của trang khác, các trang nào là các trang báo uy tín để gợi ý cho người dùng và còn ty tỷ thứ khác nữa.
Tạo project và định nghĩa Item
Tạo một project Scrapy và một Spider news giống như bài viết crawl-alonhadat:
Định nghĩa các thuộc tính cần lấy của một bài viết tin tức, bài viết này mình lấy 3 thuộc tính là URL, tiêu đề, nội dung và thời gian:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
date = scrapy.Field()
Các bạn muốn lấy thêm như là tác giả, hình ảnh, video, danh sách bài viết liên quan,… thì có thể định nghĩa thêm các trường cần lấy và viết thêm đoạn code tương ứng trong Spider.
Thiết kế cơ sở dữ liệu
Chúng ta lấy đại diện một website để phân tích, ở đây mình lấy kenh14. Vào trang chủ của kenh14 trước:
Chúng ta thấy các trang báo mỗi trang đều có một trang chủ để chứa danh sách các bài viết, danh sách các bài viết này có thể là danh sách các bài viết nổi bật hoặc danh sách tất cả bài viết sắp xếp theo thứ tự mới nhất tùy vào từng trang. Vì thế nên việc lấy bài viết từ trang chủ có thể không đủ bài viết và tạp nham vì là kết hợp của rất nhiều nhãn. Vậy chúng ta sẽ đi lấy bài viết theo từng nhãn, tùy vào từng bài toán cần giải quyết có thể chắt lọc để lấy ra các dữ liệu cần thiết, ví dụ bài toán bạn muốn phân tích về trend hàng ngày thì crawl bài viết từ các nhãn giải trí, thế giới, đời sống, truyền thông chứ không cần thiết phải crawl các bài viết từ nhãn pháp luật và xe. Các nhãn của website được thể hiện chính là các thanh menu của từng website.
Project của chúng ta đang là lập lịch để crawl hàng ngày vì vậy không giống như project Crawl Alonhadat phải next có khi tới 4000 trang để lấy dữ liệu đủ cho mô hình học máy hay học sâu thì với những project dạng này nếu là lập lịch chạy hàng ngày thì chỉ cần lấy bài viết mới nhất của ngày hôm nay hoặc cùng lắm chạy quá thêm 2-3 ngày nữa. Trong project này tại mỗi nhãn mình chỉ crawl bài viết trong page đầu tiên tìm thấy và lập lịch crawl lại hàng giờ. Nhiều bạn sợ sẽ bị trùng bài viết, nhưng đây không phải vấn đề quá lớn, chúng ta có thể lấy url của bài viết xong HASH ra để làm ID cập nhật vào cơ sở dữ liệu (Postgre, Elasticsearch,…) vì thế những bài viết trùng key sẽ được cập nhật mà không bị thêm thành nhiều bản ghi trong CSDL. Còn nếu crawl bị thiếu thì phải tính tới việc giảm tần suất từ 1h xuống còn 30p, 20p hoặc là tăng lượng bài viết mỗi lần crawl từ 1 trang lên 2-3 trang.
Mình thiết kế CSDL cho project này với 3 bảng:
- Bảng
websites:

- Bảng
x_path_categories:
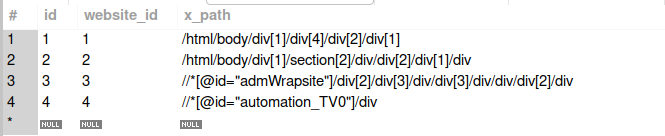
- Bảng
x_path_contents:

Với trường hợp mình xét tới trong project này là các trường hợp đơn gian nhất đó là các page danh sách bài viết của các nhãn của từng website có cấu trúc giống nhau và các page chi tiết bài viết của từng website cũng chỉ có 1 loại.
Ví dụ trang vietnamnet thì các trang vietnamnet.vn/vn/thoi-su, vietnamnet.vn/vn/kinh-doanh, vietnamnet.vn/vn/giai-tri, vietnamnet.vn/vn/the-gioi đều có cấu trúc website giống nhau nên bảng x_path_categories chỉ cần chỉ cần chứa ID của website và lưu thêm x_path thẻ bao bao bên ngoài danh sách bài viết.
Bảng x_path_contents thì khá dễ hiểu rồi, khi vào tớ một trang chi tiết thì nó là x_path để lấy ra từng thông tin chúng ta cần. Ở đây mình cũng xét một trường hợp đơn giản là một website chỉ có một loại trang chi tiết bài viết.
Kết nối cơ sở dữ liệu
Cài đặt thư viện để kết nối tới CSDL cho python:
1
pip3 install mysql-connector-python
Có cơ sở dữ liệu rồi thì giờ phải viết thêm một đoạn Code để kết nối tới CSDL cho project Scrapy.
Tạo file constants.py để lưu lại thông tin về CSDL:
1
2
3
4
5
HOST = "localhost"
USER = "root"
PASSWORD = "mysql12345"
DATABASE = "x_news"
PORT = "3306"
File connector.py sẽ lấy các thông tin tương ứng từ CSDL:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import mysql.connector
from crawler.spiders import constants
db = mysql.connector.connect(
host=constants.HOST,
user=constants.USER,
password=constants.PASSWORD,
database=constants.DATABASE,
port=constants.PORT
)
cursor = db.cursor()
# get all website in database
def get_all_websites():
cursor.execute("select * from websites")
rows = cursor.fetchall()
result = []
for row in rows:
result.append(row)
return result
# get all url categories of website
def get_categories(website_id):
cursor.execute("select * from x_path_categories where website_id = " + str(website_id))
rows = cursor.fetchall()
result = []
for row in rows:
result.append(row[2])
return result
# get x_path of title, content of url website
def get_contents(website_id):
cursor.execute("select * from x_path_contents where website_id = " + str(website_id))
rows = cursor.fetchall()
result = []
for row in rows:
result.append({"title": row[2], "content": row[3], "date": row[4]})
return result
Viết Spider
Nếu mọi người theo dõi series này của mình thường xuyên thì sẽ thấy khi mình viết Spider thường có sử dụng 3 hàm: start_requests để chuẩn bị các đường link danh sách bài viết, hàm parse_links để lấy danh sách link chi tiết bài viết từ trang danh sách bài viết và hàm parse để lấy thông tin cần thiết từ trang chi tiết bài viết.
Hàm start_requests
1
2
3
4
5
6
7
8
9
def start_requests(self):
list_websites = get_all_websites()
for website in list_websites:
domain = website[1] # get domain of website: https://vietnamnet.vn
categories = json.loads(website[2]) # get list category of website: /thoi-su, /chinh-tri
for category in categories:
link = domain + category
yield scrapy.Request(url=link, callback=self.parse_links, meta={"website_id": website[0], "domain": website[1]})
Hàm này tạo URL từng nhãn của các website từ dữ liệu trong CSDL (các dữ liệu trong CSDL các bạn xem thêm trong phần thiết kế CSDL ở bên trên), các link này chính là các link danh sách bài viết, ví dụ bản ghi đầu tiên có domain = https://vietnamnet.vn và category = ["/vn/thoi-su/", "/vn/kinh-doanh/", "/vn/giai-tri/", "/vn/the-gioi/"] thì sẽ đi từng nhãn một ghép lại thành một url hoàn chỉnh https://vietnamnet.vn/vn/thoi-su/, https://vietnamnet.vn/vn/kinh-doanh/, https://vietnamnet.vn/vn/giai-tri/, https://vietnamnet.vn/vn/the-gioi/ các URL này chính là URL danh sách bài viết của từng nhãn, giờ gửi chúng xuống hàm parse_link để làm việc tiếp theo.
Hàm parse_link
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def parse_links(self, response):
result = set()
x_path_categories = get_categories(response.meta.get("website_id"))
for x_path_category in x_path_categories:
x_path = x_path_category + "//a/@href" # get all tag a, after get all attribute href contain link of post in website news
list_href = response.xpath(x_path).extract()
for href in list_href:
if len(href) > 50 and ("http" not in href): # link have less than 50 character maybe not is link of post
result.add(response.meta.get("domain") + href)
for item in result:
yield scrapy.Request(url=item, callback=self.parse, meta={"website_id": response.meta.get("website_id")})
Ở hàm start_request chúng ta đã có gửi thêm tham số "website_id": website[0] xuống. website_id giúp chúng ta tìm được x_path của phần tử bao bên ngoài danh sách bài viết qua bảng x_path_categories. Sử dụng hàm get_categories đã viết trong phần kết nối CSDL để lấy ra x_path tương ứng, lấy ra danh sách URL của từng bài viết và gọi tới hàm parse cuối cùng.
Lưu ý là vẫn cần gửi website_id xuống hàm parse để có thể lấy các thông tin x_path trong bài viết được định nghĩa trong CSDL tại bảng x_path_contents.
Hàm parse
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def parse(self, response):
posts = get_contents(response.meta.get("website_id"))
for post in posts:
content = response.xpath(post["content"] + "").extract_first()
title = response.xpath(post["title"] + "//text()").extract_first()
date = response.xpath(post["date"] + "//text()").extract_first()
content = self.normalize(content)
title = self.normalize(title)
date = self.normalize(date)
crawlerItem = CrawlerItem()
crawlerItem['content'] = content
crawlerItem['title'] = title
crawlerItem['date'] = date
crawlerItem['url'] = response.url
yield crawlerItem
Hàm này thì khá rõ ràng với mục đích của nó rồi, với từng x_path tương ứng trong CSDL lấy ra dữ liệu tương ứng và trả về CrawlerItem.
Chạy và lập lịch project
Bài viết nằm trong series về Crawl nên mình cũng nói chủ yếu về crawl và cách lưu trữ để crawl mà ít nói về luồng của nó.
Các bạn có thể theo dõi đầy đủ project với luồng dữ liệu từ lập lịch crawl -> hàng đợi -> Spark Streaming -> Spark ML tại https://github.com/trannguyenhan/X-news (Source code này cũng từ khá lâu, một số các cái liên quan tới Kibana, ElastichSearch cũng không được cập nhật lên repo nên các bạn dùng tham khảo là chính thôi nha)
Chạy project với câu lệnh:
1
scrapy crawl news
Project này mình đang viết file pipeline với đầu ra dữ liệu được đẩy vào một hàng đợi Kafka để một bên khác nhận và xử lý dữ liệu phía sau, file pipelines.py được viết như dưới đây:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from kafka import KafkaProducer
import json
class CrawlerPipeline:
def open_spider(self, spider):
self.producer = KafkaProducer(bootstrap_servers=['localhost:9092'], \
value_serializer=lambda x: json.dumps(x, ensure_ascii=False).encode('utf-8'))
self.topic = "x_news_1"
def process_item(self, item, spider):
line = ItemAdapter(item).asdict()
self.producer.send(self.topic, value=line)
return item
Toàn bộ project Crawl này các bạn có thể tham khảo tại link GITHUB: https://github.com/demanejar/crawler-1000news.
Để lập lịch cho con Spider chạy hàng ngày có thể sử dụng crontab, cái này hoạt động khá đơn giản, copy lệnh chạy vào file nó quét qua là được. Xem thêm về cron tại https://viblo.asia/p/task-schedule-trong-laravel-naQZRkOqlvx#_crontab-0.
Vì website không có mục bình luận dưới bài viết nên mọi người thảo luận và góp ý cho mình tại GITHUB DISCUSSION này nha: https://github.com/orgs/demanejar/discussions/1.