
Apache nifi được sử dụng để tự động hóa và kiểm soát các luồng dữ liệu giữa các hệ thống. Nó cung cấp cho chúng ta một giao diện trên nền web mà có thể thu thập, xử lý, phân tích dữ liệu.
NiFi được biết đến với khả năng xây dựng luồng chuyển dữ liệu tự động giữa các hệ thống. Đặc biết là hỗ trợ rất nhiều kiểu nguồn và đích khác nhau như:hệ thống file, cơ sở dữ liệu quan hệ, phi quan hệ,… Ngoài ra Nifi sẽ hỗ trợ các thao tác với dữ liệu như lọc chỉnh sửa, thêm bớt nội dung.
Các thành phần chính
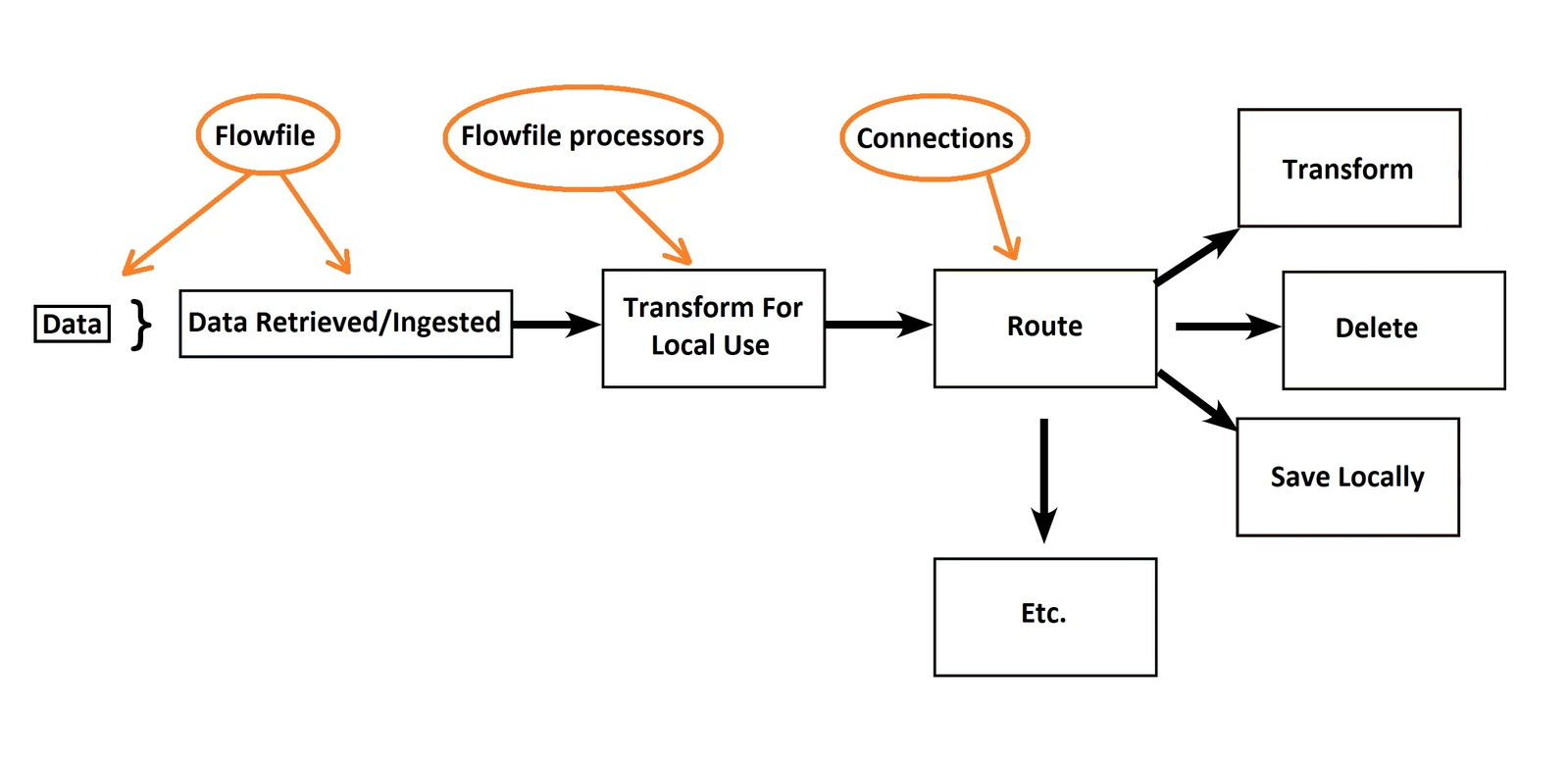
Flowfile
Đại diện cho đơn vị dữ liệu được thực hiện trong luồng ví dụ như 1 bản ghi text, 1 file ảnh… gồm 2 phần:
- Content: chính là dữ liệu nó đại diện
- Attribute: thuộc tính của flow file (key-value)
Flowfile processor
Đây là những thứ thực hiện công việc trong nifi, bên trong nó đã có chứa sẵn code thực thi các tác vụ trong các trường hợp với input và output. Khối xử lý sinh ra các flowfile. Các processor hoạt động song song với nhau
Connection
Connection đóng vai trò kết nối giữa các processors. Ngoài ra nó còn là một hàng đợi chứa các flowfile chưa được xử lý:
- Xác định thời gian flowfile tồn tại trong queue
- Phân chia flowfile đến các node trong cụm (load balancing)
- Xác định tần suất flowfile nhả ra cho hệ thống
Kiến trúc hệ thống
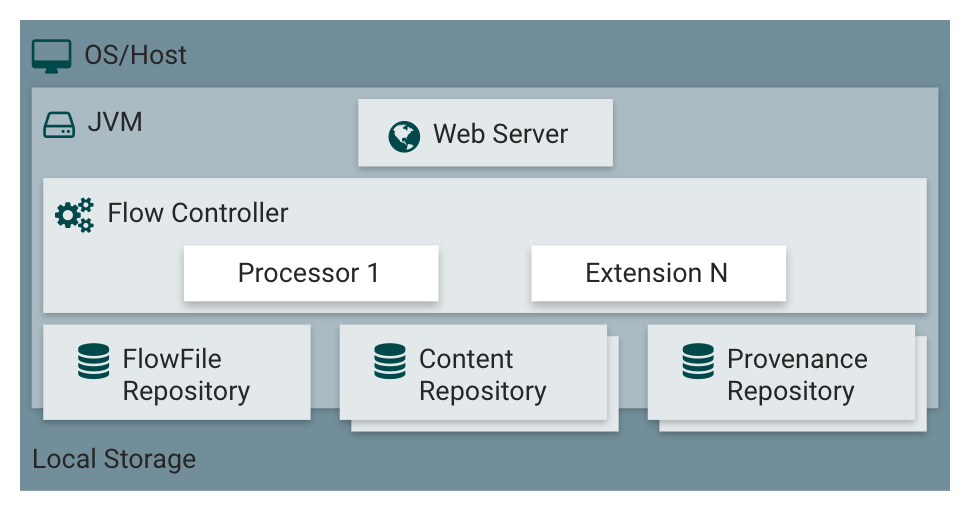
- Web server: cung cấp giao diện cho người dùng sử dụng các thao tác
- Flow Controller: cung cấp tài nguyên cho quá trình hoạt động của hệ thống
- Extensions: Bao gồm các thành phần xây dựng nên luồng dữ liệu trong nifi: các processors có nhiệm vụ xử lý, điều hướng; Các log, Controller service chứa các chức năng dùng cho các extensions khác
- Flowfile repository: Chỉ lưu lại các metadata của flowfile vì flowfile lưu dữ liệu rồi
- Content repository: Lưu trữ dữ liệu thực đang được xử lý trong luồng. Nifi lưu lại tất cả các phiên bản dữ liệu trước và sau khi được xử lý
- Provenance repository: Lưu lại toàn bộ lịch sử của flowfile
Các đặc điểm nổi bật Nifi
Khả năng quản lý nguồn dữ liệu
- Đảm bảo tính an toàn: Mỗi đơn vị dữ liệu trong luồng sẽ được lưu dưới dạng 1 object là flowfile. Nó sẽ ghi lại thông tin về khối dữ liệu đang được xử lý ở đâu, di chuyển đi đâu… Provenance Repo được sử dụng để lưu các flowfile giúp ta có thể truy vết
- Data Buffering: Giải quyết vấn đề tốc độ dữ liệu ghi vào nhanh hơn dữ liệu đọc giữa hai khối xử lý. Dữ liệu này sẽ được lưu ở RAM, nếu quá một ngưỡng thì sẽ được lưu xuống ổ cứng
- Thiết lập độ ưu tiên: Trong xử lý dữ liệu có những dữ liệu ta phải xử lý ưu tiên
- Đánh đổi tốc độ và khả năng chịu lỗi: Nifi hỗ trợ cài đặt để cân bằng 2 yếu tố này
Sử dụng dễ dàng
- Nifi hỗ trợ UI cho việc xây dựng luồng dữ liệu
- Tính tái sử dụng khi ta có thể lưu được các luồng dữ liệu thành 1 template
- Theo dõi trực quan lịch sử
Mở rộng theo chiều ngang
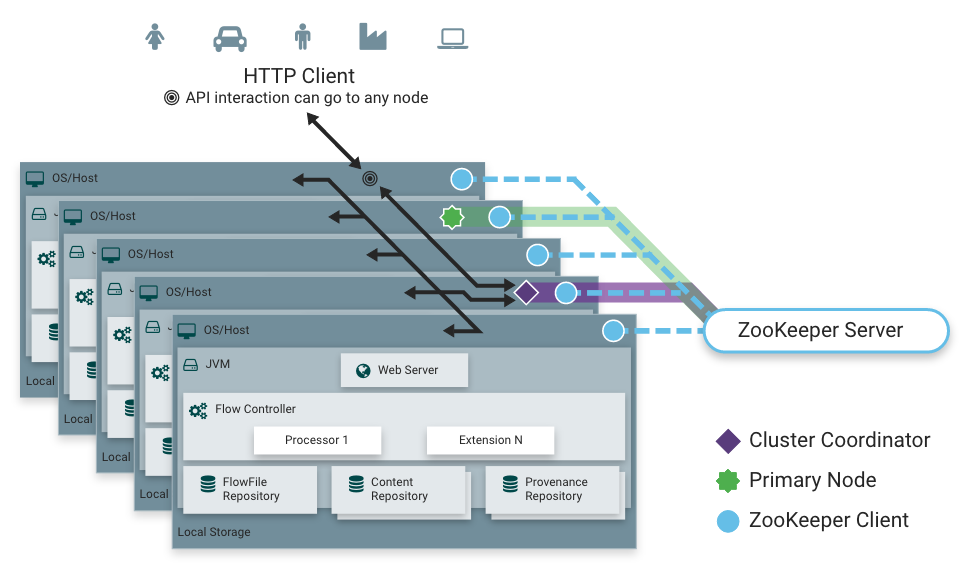
Giả sử với nifi chỉ chạy trên 1 server mà không xử lý được thì chúng ta làm cách nào -> chạy cùng 1 dataflow trên nhiều server. Người quản trị không cần sửa đổi tất cả các dataflow ở các server khác nhau mà chỉ cần thay đổi một lần sẽ tự động sao chép sang các server khác.
Cụm Nifi tuân theo nguyên tắc Zero-master nghĩa là các server nào cũng có công việc giống nhau nhưng xử lý dữ liệu khác nhau. Một Node sẽ được chọn làm quản lý cụm (Cluster Coordinator) thông qua zookeeper. Tất cả các node trong cụm sẽ gửi trạng thái cho node này, và node này có trách nhiệm ngắt kết nối các node mà không gửi trạng thái trong một khoảng thời gian nào đó. Ngoài ra Node này sẽ chịu trách nhiệm cho việc node mới tham gia vào cụm. Node mới phải kết nối trước với node này để dữ liệu được cập nhật.