
Trong quá trình làm bài tập lớn môn lưu trữ và xử lý dữ liệu lớn ở trường mình có biết đến kafka và sử dụng cho project của mình. Tuy nhiên lúc đó mình mới chỉ biết đơn giản nó là một message queue để đổ dữ liệu vào giúp việc đọc ghi từ nguồn vào đích không phụ thuộc lẫn nhau(loosely couple). Vậy nên sau đó mình có tìm hiểu các khái niệm và cách hoạt động một cách chi tiết hơn nên viết vào đây.
Apache Kafka là một hệ thống được tạo ra bởi linkedin nhằm phục vụ cho việc xử lý dữ liệu theo luồng (stream process) sau đó được open-source. Ban đầu nó được nhìn nhận dưới dạng một message queue nhưng sau này được phát triển thành một nền tảng xử lý phân tán (distributed streamming platform - nhiều cái thuật ngữ dịch ra tiếng Việt khó quá !!).
Vấn đề trong dữ liệu lớn
3V trong big data: dữ liệu với khối lượng lớn được sinh ra theo từng giây và định dạng khác nhau ()có cấu trúc, bán cấu trúc, không có cấu trúc ). Để xử lý được vấn đề nêu trên ta cần phải tập hợp được dữ liệu từ các nguồn như hdfs, nosql db, rdbms,… Tuy nhiên làm thế nào mà ta có thể xử lý đồng thời và không bị phụ thuộc lẫn nhau (looosely couple) đối với những nguồn dữ liệu kia -> Kafka là một giải pháp.
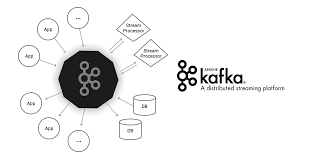
Một số thành phần trong Kafka
Tổng quan
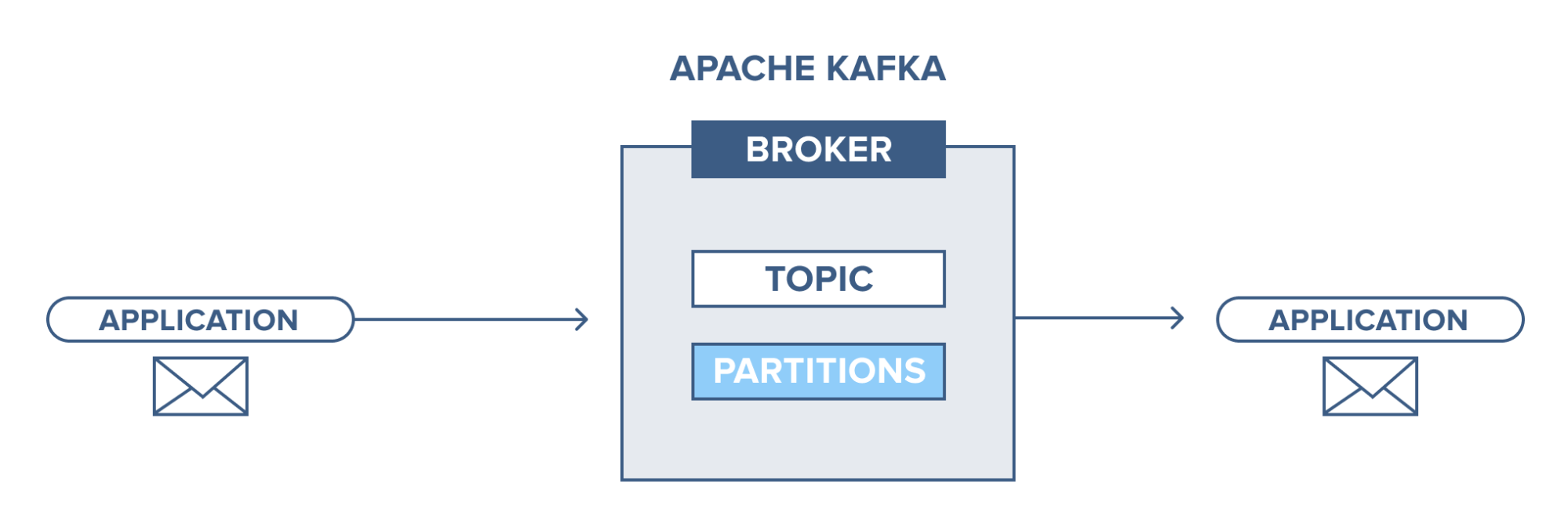
Một ứng dụng kết nối với hệ thống kafka này và gửi thông điệp(bản ghi) tới topic. Thông điệp có thể là bất cứ gì ví dụ như log của hệ thống, sự kiện,… Sau đó một ứng dụng khác kết nối và lấy thông điệp(bản ghi) trong topic. Dữ liệu vẫn được lưu trữ tại ổ đĩa cho tới khi hết thời gian đã được định sẵn (retention time).
Broker
Ở đây ta đề cập đến cụm kafka, trong đây ta sẽ có các server chạy kafka. Tại đây chứa các topic được producer gửi dữ liệu vào và các consumer sẽ lấy dữ liệu ở đây.
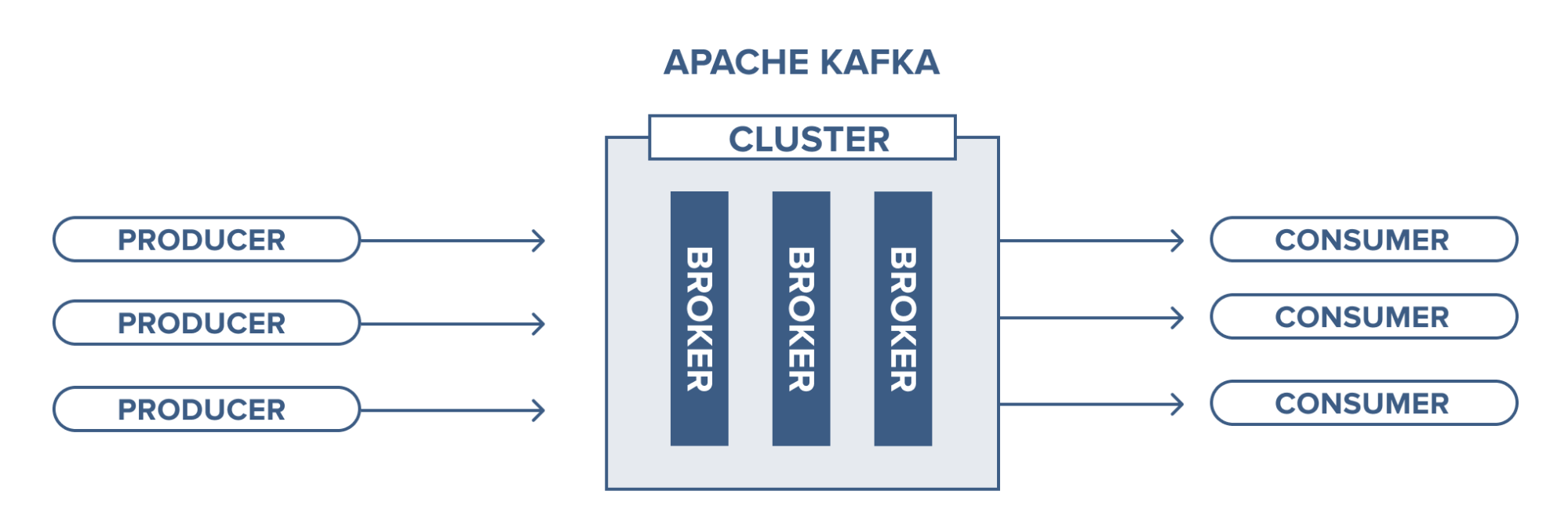
Việc quản lý các broker sẽ được thực hiện bởi zookeeper. Trong một cụm kafka cũng có thể có nhiều hơn 1 zookeeper.
Topic
Topic là nơi mà bản ghi dữ liệu được lưu lại và sử dụng.
Các bản ghi được đưa vào topic sẽ có 1 “offset” là chỉ số vị trí của chúng để có thể giúp consumer xác định được và lấy ra. Consumer có thể điều chỉnh cái vị trí này để lấy ra theo thứ tự mong muốn ví dụ như khi ta muốn xử lý từ đầu thì có thể đặt offset sớm nhất.
Topic partition
Như đã nói ở phần trước thì mỗi bản ghi đều có 1 offset riêng và trong topic ta có khái niệm partition tức phân mảnh. Một topic có thể có nhiều partition và các bản ghi sẽ được lưu trong partition đó với giá trị offset. Điều này sẽ giúp consumer đọc dữ liệu từ topic song song, ví dụ 1 topic có 4 partitions ta có 1 consumer và consumer này sẽ đọc từ 4 partitions của topic trên.
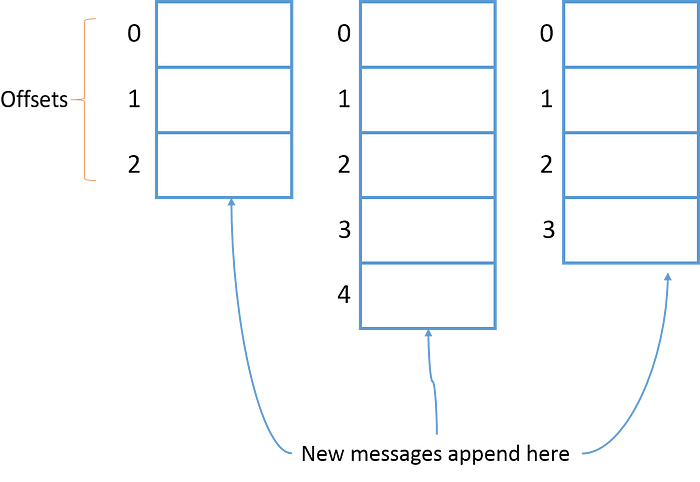
Các partition của topic có thể nằm trên các broker khác nhau vậy nên điều này sẽ giúp cho topic có thể truy cập được từ nhiều broker.
Việc sao lưu dữ liệu của topic là khi ta cài đặt replication-factor lúc tạo topic. Ví dụ như khi ta tạo một topic với 3 partitions và replication-factor là 3 thì sẽ được kết quả như hình dưới. Điều này đảm bảo tính khả dụng (availability).
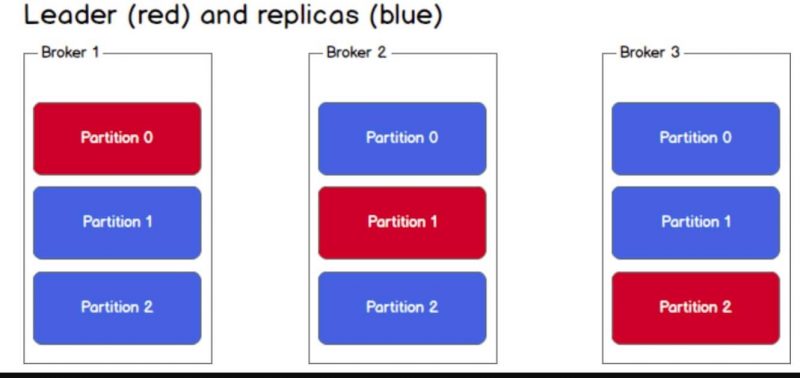
Cơ chế ở đây sẽ là Leader - Follower (partitions). Khi dữ liệu được đẩy vào leader sẽ chịu trách nhiệm phần đọc ghi. Các follower chỉ đóng vai trò sao chép lại, ta cũng không thể đọc được vì kafka không cho phép. Khi leader sập thì sẽ bầu ra leader mới từ các follower và đồng bộ lại dữ liệu.
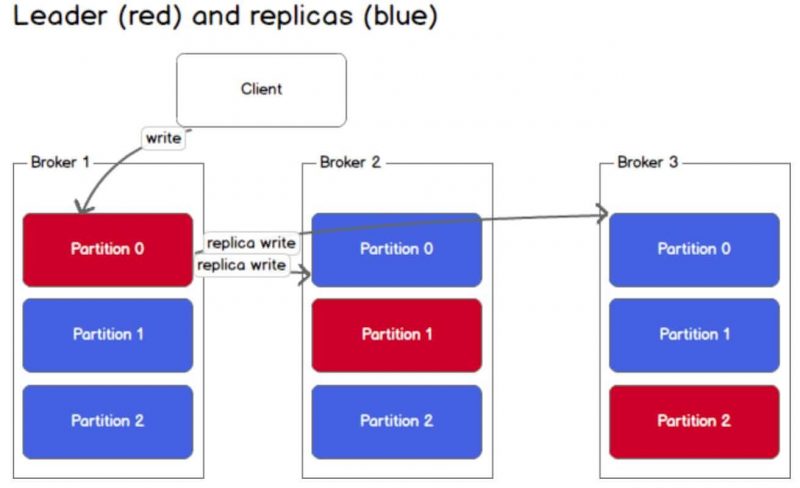
Việc lưu trữ Leader - Follower sẽ được lưu vào metadata được quản lý bởi zookeeper
Producer
Producer có nhiệm vụ gửi dữ liệu vào topic trong broker.
Producer ghi một thông điệp như thế nào ?
Trong cụm kafka, producer chỉ ghi dữ liệu vào partition leader của topic. Đối với một topic nói riêng ta không nói đến việc leader - follower ở đây, nếu có 1 dữ liệu mới vào mà topic producer gửi có nhiều hơn 1 topic thì chỉ có 1 partition nhận được dữ liệu đó.
3 cách mà producer có thể ghi vào topic:
send(key,value,topic,partition): chỉ định rõ partition mà message được ghi vàosend(key,value,topic): Sẽ có 1 hàm hash tiến hành tính giá trị của key để đưa vào partition phù hợpsend(key,value): Dữ liệu được đưa vào partition theo cơ chế round-robin
Consumer
Consumer lấy dữ liệu trong các topic trong broker mà nó subcribe.
Consumer có thể đọc bất cứ offset nào trong topic vậy nên nó có thể vào trong cụm bất cứ lúc nào.
Consumer lấy thông điệp như thế nào ?
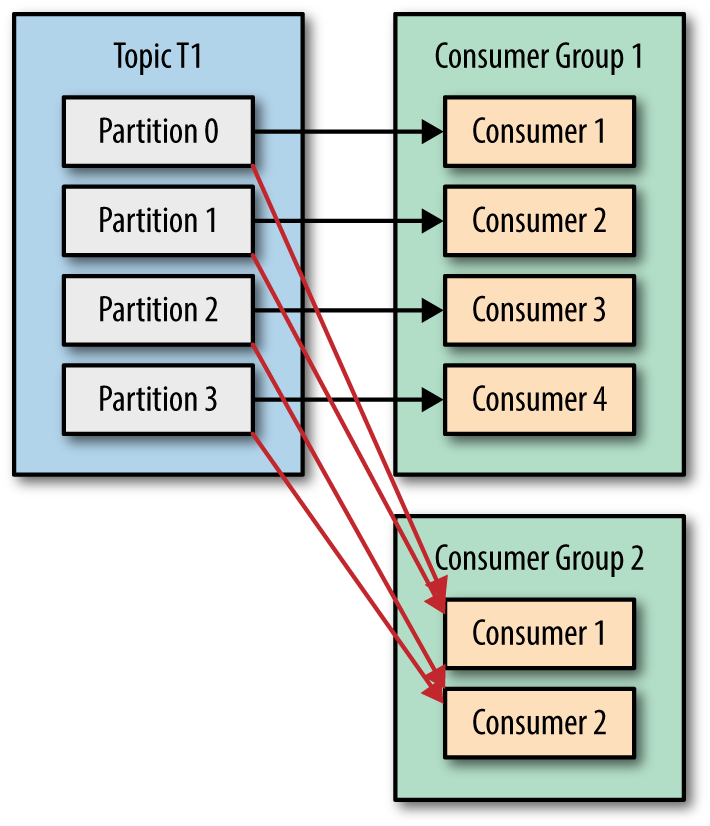
Giống như producer consumer phải tìm kiếm trước metadata và đọc dữ liệu từ leader-partition. Nếu dữ liệu mà lớn thì có thể consumer sẽ bị lag -> để giải quyết Consumer Group.
Consumer group là một nhóm các consumer cùng id. Trong đó mỗi consumer sẽ chỉ gán với 1 partitions. Nếu số lượng partition lớn hơn số consumer thì consumer có thể nhận được nhiều hơn, nếu nhỏ hơn thì sẽ có consumer không nhận được dữ liệu. Việc gán partition cho consumer sẽ được chịu trách nhiệm bởi Group Coordinator - 1 trong các broker của cụm
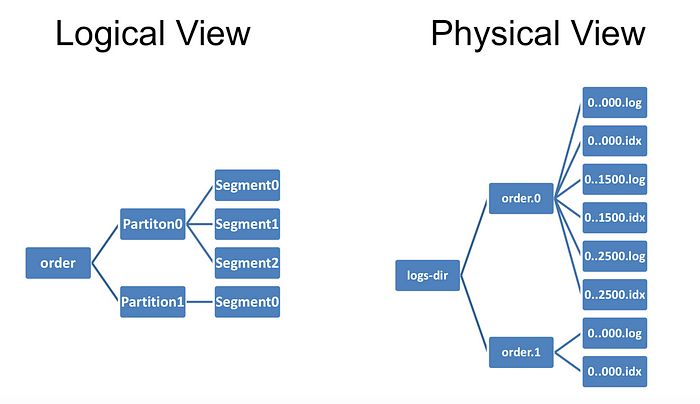
Lưu trữ dữ liệu trong kafka
Tất cả dữ liệu được lưu trên ổ đĩa chứ không phải trên ram và được sắp xếp tuần tự theo 1 cấu trúc dữ liệu là log. Việc này vẫn khiến kafka có thể nhanh như vậy là bởi một số lý do dưới đây:
- Các message được nhóm lại với nhau tạo thành 1 segment -> giảm chi phí sử dụng tài nguyên mạng, consumer sẽ tìm 1 segment -> giảm tải disk
- Dữ liệu lưu dưới dạng nhị phân làm cho nó tối ưu khả năng zero-copy
- Các dữ liệu tại producer đã được nén dùng các thuật toán nén như gzip và sau đó giải nén tại consumer
- Việc đọc/ghi trên cấu trúc dữ liệu log là 0(1) (No random disk access)
Usecase
Đối với trang thương mại điện tử, mỗi click hay các hành động của người dùng trên trang đó có thể phản án thói quen mua sắm của họ. Các dữ liệu này sẽ được đưa vào kafka để xử lý theo thời gian thực giúp đưa ra gợi ý ngay tại họ thời điểm họ trên trang web. Sau đó việc xử lý theo luồng sẽ được tổng hợp lại với dữ liệu mới để có thể gợi ý với lần vào tiếp theo. Việc sử dụng kafka sẽ không liên quan đến cơ sở dữ liệu hệ thống nên đảm bảo được ổn định.
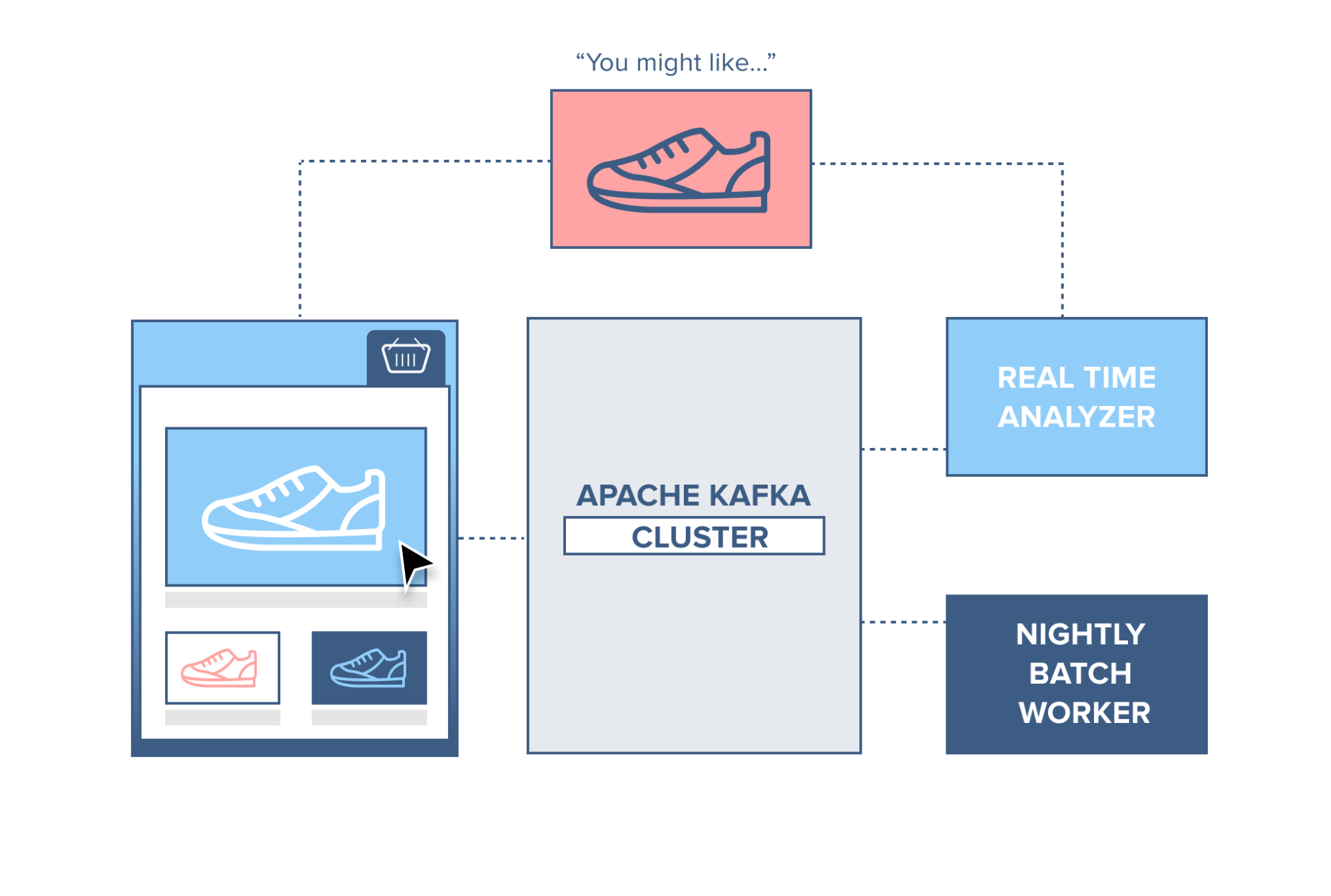
Còn khá nhiều ứng dụng nữa nhưng mình không muốn tập trung vào phần này, mọi người có thể tìm hiểu thêm.
Cài đặt và sử dụng Kafka
Cài Zookeeper
Để triển khai nhanh và dễ sử dụng mình sẽ sử dụng docker. Đầu tiên ta sẽ tạo một folder kafka rồi tạo 1 file docker-compose trong đó
1
2
mkdir kafka
cd kafka
Trước hết phải có Zookeeper, trong file docker-compose mình sẽ config như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
services:
zookeeper:
image: zookeeper:3.4.9
hostname: zookeeper
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zookeeper:2888:3888
volumes:
- ./data/zookeeper/data:/data
- ./data/zookeeper/datalog:/datalog
Sau khi xong ta chạy lệnh docker-compose up. container zookeeper sẽ được tải về và ta sẽ chạy được zookeeper ở cổng 2181 như trong config.
Cài Kafka standalone
Mình sẽ tạm thời tắt tiến trình docker chạy cho zookeeper đi và tiến hành chỉnh sửa tiếp trong file docker-compose với nội dung như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
kafka1:
image: confluentinc/cp-kafka:5.3.0
hostname: kafka1
ports:
- "9091:9091"
environment:
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka1:19091,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9091
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- ./data/kafka1/data:/var/lib/kafka/data
depends_on:
- zookeeper
Sau khi chỉnh sửa xong thử chạy docker-compose up. Mình sẽ thử tạo luôn topic với lệnh:
1
docker exec -it kafka_kafka1_1 kafka-topics --zookeeper zookeeper:2181 --create --topic my-topic --partitions 1 --replication-factor 1\n
Cài đặt Kakfa với nhiều broker
Để chạy một cụm kafka mình sẽ phải thêm các broker khác. ở đây sẽ có thêm 2 broker bằng việc tiếp tục chỉnh sửa file docker-compose.
Thêm broker thứ 2 với id là 2 tại cổng 9089:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
kafka2:
image: confluentinc/cp-kafka:5.3.0
hostname: kafka2
ports:
- "9089:9089"
environment:
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka2:19092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_BROKER_ID: 2
volumes:
- ./data/kafka2/data:/var/lib/kafka/data
depends_on:
- zookeeper
Tương tự với broker thứ 3 tại cổng 9090:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
kafka3:
image: confluentinc/cp-kafka:5.3.0
hostname: kafka3
ports:
- "9090:9090"
environment:
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka3:19093,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 3
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- ./data/kafka3/data:/var/lib/kafka/data
depends_on:
- zookeeper
Giờ mình sẽ thử kiểm tra xem cụm chạy được không bằng cách tạo một topic mới với replication-factor = 3 (xem topic có được phân bố trên cả 3 brokers không):
1
docker exec -it kafka_kafka1_1 kafka-topics --zookeeper zookeeper:2181 --create --topic my-topic-three --partitions 1 --replication-factor 3\n
Tham khảo
A simple apache kafka cluster with docker kafdrop