
MapReduce là một kỹ thuật xử lý và là một mô hình lập trình cho tính toán phân tán để triển khai và xử lý dữ liệu lớn. MapReduce chứa 2 tác vụ quan trọng là map và reduce. WordCount là một ví dụ điển hình cho MapReduce mà sẽ được mình minh họa trong bài viết này
Tại sao Mapreduce lại ra đời?
Như phần giới thiệu thì ai cũng biết là MapReduce là viết gộp lại của map và reduce là 2 hàm chính trong phương pháp lập trình này. Mô hình lập trình này bắt nguồn chính là từ Google, hay rõ ràng hơn là từ 1 bài báo của Google. Vấn đề đặt ra là cần phải song song hóa các tính toán, phân tán dữ liệu và phải có khả năng chịu lỗi cao.
MapReduce đơn giản và mạnh mẽ cho phép tự động song song hóa và phân phối các phép tính quy mô lớn, kết hợp với việc triển khai mô hình lập trình này để đạt được hiệu suất cao trên các cụm máy tính lớn hàng trăm, hàng nghìn máy tính.
Mô hình lập trình
Mô hình của mapreduce phải nói là cực kì đơn giản và dễ hình dung. Lập trình viên sẽ chỉ phải viết lại 2 hàm trong mô hình lập trình MapReduce là hàm map và hàm reduce.
Ví dụ WordCount
WordCount là một bài toán kinh điển để minh họa cho MapReduce, ý tưởng của MapReduce được viết giống với đoạn mã giả sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
map(string key, string value){
// key: document name
// value: document value
for each word w in value{
ComputeIntermediate(w,"1"); // tính toán các giá trị key/value trung gian
}
}
reduce(string key, List values){
int result = 0;
for each v in values {
result += ParseInt(v); // tổng hợp giá trị
}
Write(key, result); // ghi kết quả
}
Ví dụ bây giờ chúng ta cần thực hiện 1 task là đếm số lần xuất hiện của mỗi từ trong 1 văn bản. Đầu tiên chúng ta sẽ chia tách văn bản đó thành các dòng, mỗi dòng sẽ được đánh 1 số thứ tự. Đầu vào của hàm Map sẽ là các cặp key/value chính là số thứ tự dòng / đoạn văn bản trên dòng đó
Trong Map chúng ta sẽ xử lý tách từng từ trong 1 dòng ra và gán cho chúng giá trị tần suất suất hiện ban đầu là 1
Sẽ có một tiến trình ở giữa giúp việc gộp các output đầu ra của Map có cùng key với nhau thành 1 mảng các giá trị
Đầu vào của Reduce sẽ là cặp key/value là từ / và 1 mảng là tần suất xuất hiện của từ đó. Trong Reduce chúng ta chỉ cần thực hiện cộng các giá trị trong mảng và đưa ra kết quả chính là số lần xuất hiện của từng từ trong văn bản đầu vào
Để hình dung rõ hơn, bạn có thể xem hình ảnh sau:
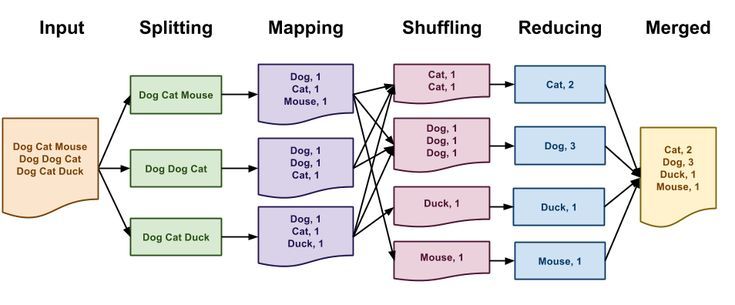
Khi lập trình MapReduce các input, output cho 2 hàm Map và Reduce là thứ mà lập trình viên phải xác định trước khi làm. Đối với bài WordCount có vẻ đơn giản, nhưng trong các bài toán phức tạp hơn việc đưa về mô hình MapReduce chưa hẳn là đã dễ.
MapReduce Model
Tổng kết lại, 2 hàm Map và Reduce sẽ có đầu vào, đầu ra sẽ được thu gọn lại giống như đoạn mã giả dưới đây:
1
2
map() : (k1, v1) => list(k2, v2)
reduce() : (k2, list(v2)) => list(v2)
Kết luận
MapReduce là không phải là mô hình duy nhất giúp song song hóa tốt mà còn rất nhiều các mô hình lập trình khác giúp xử lý dữ liệu lớn bằng cách song song hóa. Tuy nhiên, MapReduce là đơn giản, dễ tiếp cận.
Để hiểu hơn nữa về MapReduce bạn có thể tìm hiểu và đọc thêm bài báo của Google Mapreduce : Simplified Data Processing on Large Clusters, dĩ nhiên là trong bài báo của Google không chỉ đề cập tới một mô hình đơn giản này mà con là những vấn đề sâu hơn như là những yêu cầu khi xây dựng 1 hệ thống phân tán dựa trên mô hình MapReduce, các chức năng cải tiến, hiệu năng và các kinh nghiệm. Trong bài viết này mình chỉ chủ yếu nói về ý tưởng của MapReduce, các phần còn lại mình sẽ viết tiếp trong bài viết vê một framework cụ thể là Hadoop MapReduce.