
Hệ sinh thái Apache Hadoop đề cập đến các thành phần khác nhau của thư viện phần mềm Apache Hadoop; nó bao gồm các dự án mã nguồn mở cũng như một loạt các công cụ bổ sung hoàn chỉnh khác. Một số công cụ nổi tiếng nhất của hệ sinh thái Hadoop bao gồm HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, Zookeeper,…
Với HDFS, Hadoop MapReduce mình sẽ có các bài viết riêng sau, trong bài viết về Hadoop Ecosystem này chỉ mang tính chất liệt kê và giới thiệu các thành phần trong hệ sinh thái Hadoop.
HDFS
Hadoop Distributed File System (HDFS) là một trong những hệ thống lớn nhất trong hệ sinh thái Hadoop và là hệ thống lưu trữ chính của Hadoop.
HDFS cung cấp khả năng lưu trữ tin cậy và chi phí hợp lí cho khối dữ liệu lớn, tối ưu cho các tập tin kích thước lớn ( từ vài trăm MB cho tới vài TB). HDFS có không gian cây thư mục phân cấp giống như các hệ điều hành Unix, Linux.
Do các tính chất của dữ liệu lớn và hệ thống tập tin phân tán nên việc chỉnh sửa là rất khó khăn, Vì thế mà HDFS chỉ hỗ trợ việc ghi thêm dữ liệu vào cuối tệp (append), nếu bạn muốn chỉnh sửa ở bất kì chỗ khác chỉ có cách là viết lại toàn bộ tệp với các phần sửa đổi và thay thế lại tệp cũ. HDFS tuân theo tiêu chí “ghi một lần và đọc nhiều lần”.
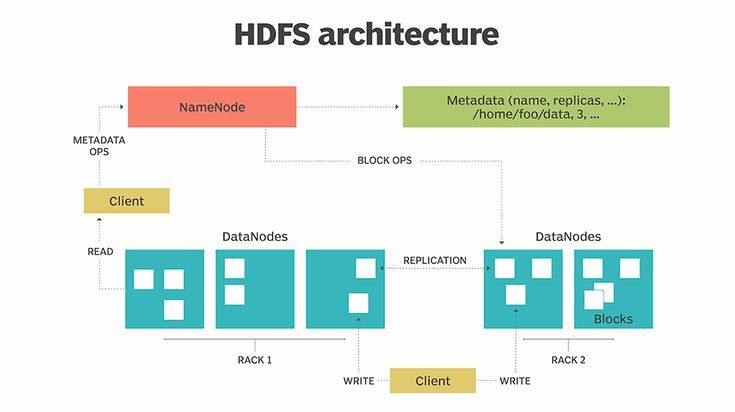
Kiến trúc của HDFS là kiến trúc Master/Slave, HDFS master (namenode) quản lý không gian tên và các metadata, giám sát các datanode. HDFS slave (datanode) trực tiếp thao tác I/O với các chunks.
Nguyên lý thiết kế của HDFS là:
- Chỉ ghi thêm (append) => giảm chi phí điều khiển tương tranh
- Phân tán dữ liệu
- Nhân bản dữ liệu
- Cơ chế chịu lỗi
Hive
![]()
Apache Hive là một công cụ cơ sở hạ tầng kho dữ liệu để xử lý dữ liệu có cấu trúc trong Hadoop. Hive tạo điều kiện cho việc đọc, ghi và quản lý các tập dữ liệu lớn nằm trong bộ lưu trữ phân tán bằng cách sử dụng SQL (tuy nhiên hãy nhớ Hive không phải là một CSDL quan hệ).
Hive cung cấp ngôn ngữ kiểu SQL để truy vấn được gọi là HiveQL hoặc HQL.
Để tìm hiểu thêm về Hive bạn có thể xem thêm tại trang chủ của Hive: https://hive.apache.org/.
HBase
![]()
HBase là một cơ sở dữ liệu dạng column-family, lưu trữ dữ liệu trên HDFS, được xem như là hệ quản trị CSDL của Hadoop.
Để hiểu rõ hơn về Column-Family bạn có thể đọc thêm bài báo về Bigtable: Bigtable: A Distributed Storage System for Structured Data
Xem thêm về Apache HBase tại: https://hbase.apache.org/.
Hadoop MapReduce

Đây là một lớp xử lý dữ liệu khác của Hadoop. Nó có khả năng xử lý dữ liệu có cấu trúc và phi cấu trúc lớn cũng như quản lý song song các tệp dữ liệu rất lớn bằng cách chia công việc thành một tập hợp các nhiệm vụ độc lập (sub-job).
Để xem thêm về ý tưởng của MapReduce bạn có thể xem lại bài viết Mô hình lập trình MapReduce cho Bigdata.
Apache Zookeeper
![]()
Zookeeper là một dịch vụ cung cấp các chức năng phối hợp phân tán độ tin cậy cao:
- Quản lý các thành viên trong nhóm máy chủ
- Bầu cử leader
- Quản lý thông tin cấu hình động
- Giám sát trạng thái hệ thống
Đây là một dịch vụ lõi, tối quan trọng trong các hệ thống phân tán.
Xem thêm về Zookeeper tại https://zookeeper.apache.org/.
YARN
Apache Hadoop YARN (Yet Another Resource Negotiator) được giới thiệu từ Hadoop 2.0 là một công nghệ hỗ trợ quản lý tài nguyên và lập lịch công việc trong Hadoop.
Chúng ta có thể thấy sự hiện diện của YARN chính là 2 daemons:
- Node Managers
- Resource Manager
Apache Sqoop
Sqoop là một công cụ cho phép trung chuyển dữ liệu theo khối từ Apache Hadoop và các CSDL có cấu trúc như CSDL quan hệ.
Hiện tại Apache Sqoop đã ngừng hoạt động, bạn có thể xem thêm về Sqoop tại https://sqoop.apache.org/.
Apache Kafka
![]()
Apache Kafka là một hệ thống được tạo ra bởi linkedin nhằm phục vụ cho việc xử lý dữ liệu theo luồng (stream process) sau đó được open-source. Ban đầu nó được nhìn nhận dưới dạng một message queue nhưng sau này được phát triển thành một nền tảng xử lý phân tán.
Trên website đã có 1 bài viết giới thiệu về Kafka, bạn có thể xem thêm TẠI ĐÂY.
Tham khảo: https://databricks.com/, https://www.apache.org/