
Spline là một công cụ OpenSource cho phép tự động theo dõi Data Lineage và Data Pipeline Structure. Công việc phổ biến nhất của nó là theo dõi và trực quan hóa Data Lineage cho Spark.
Tổng quan Spline
Spline là một công cụ mã nguồn mở và miễn phí để theo dõi tự động dòng dữ liệu (data lineage) và cấu trúc đường dẫn dữ liệu (pipeline structure) trong các dự án. Phổ biến là việc sử dụng Spline cho theo dõi và trực quan hóa Data Lineage cho Spark Job.
Spline được tạo ra như một công cụ theo dõi dành riêng của Spark, tuy nhiên sau đó dự án đã được mở rộng để phù hợp với nhiều các dự án khác ngoài Apache Spark. Mặc dù vậy thì Spline vẫn được biết tới như công cụ theo dõi tự động dòng dữ liệu dành cho Spark Job.
Spline gồm 3 thành phần chính:
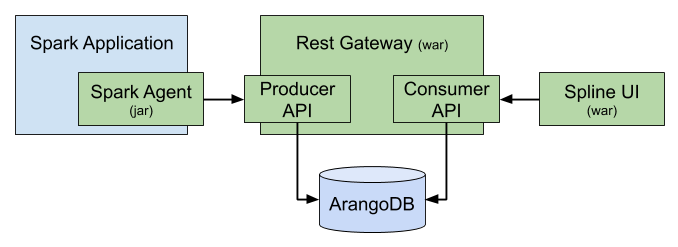
Spline Server: Spline server là phần quan trọng nhất của Spline, nó đảm nhận nhiệm vụ thu thập và xử lý dữ liệu, nhận thông tin data lineage được gửi về từ agent thông qua producer API và lưu chúng vào CSDL ArangoDB và cung cấp một consumer API để đọc và truy vấn lineage data. Consumer API được sử dụng bởi Spline UI hoặc bất kỳ ứng dụng bên thứ 3 nào muốn trực quan hóa kết quả data lineage được Spline thu thập
Spline Agents: Spline Agent là một thành phần sẽ được khai báo nằm trong ứng dụng Spark để lấy dữ liệu data lineage của Spark. Mỗi lần Spark Job chạy, Spline Agent sẽ lấy thông tin data lineage và gửi sang producer API để Spline Server sử lý và lưu vào CSDL
Spline UI: là công cụ để trực quan hóa dòng dữ liệu của Spark Job được Spline thu thập. Spline UI có thể được thay thế bằng các ứng dụng của bên thứ 3 khác ví dụ như Open Metadata
Lưu ý: Các phiên bảng từ spline 0.3 trở về trước sử dụng MongoDB làm CSDL, tuy nhiên từ các phiên bản 0.4 Spline thay thế chúng bằng một CSDL dạng document mạnh mẽ hơn là ArangoDB.
Spline có thể sử dụng REST API hoặc Kafka để làm phương tiện truyền tải dữ liệu, trong bài viết này mình sẽ chỉ đề cập tới việc sử dụng REST API
Cài đặt Spline
Để dựng Spline thì cần dựng lên Spline Server, Spline UI và cấu hình Spline Agent cho Spark. Spline Server và Spline UI đều chạy trên một máy chủ Tomcat. Chúng ta có thể tải về các bản war của Spline Server và Spline UI và chạy chúng với tomcat tại đây:
- Spline REST Gateway: za.co.absa.spline:rest-gateway:0.7.8
- Spline UI: za.co.absa.spline.ui:spline-web-ui:0.7.5
Việc cài đặt Spline thủ công qua Tomcat thường ít được sử dụng hiện nay, Chúng thường được sử dụng trên các công nghệ mà cài các bản đóng gói như Ambari hoặc các dự án có yêu cầu cụ thể khác, thay vào đó có thể sử dụng Docker để thay thế cho việc cài đặt.
Cài đặt Spline qua Docker:
- Bước 1: Clone project
1
git@github.com:trannguyenhan/docker-installer.git
- Bước 2: cd tới thư mục spline
1
cd spline
- Bước 3: Chạy spline
1
docker-compose up
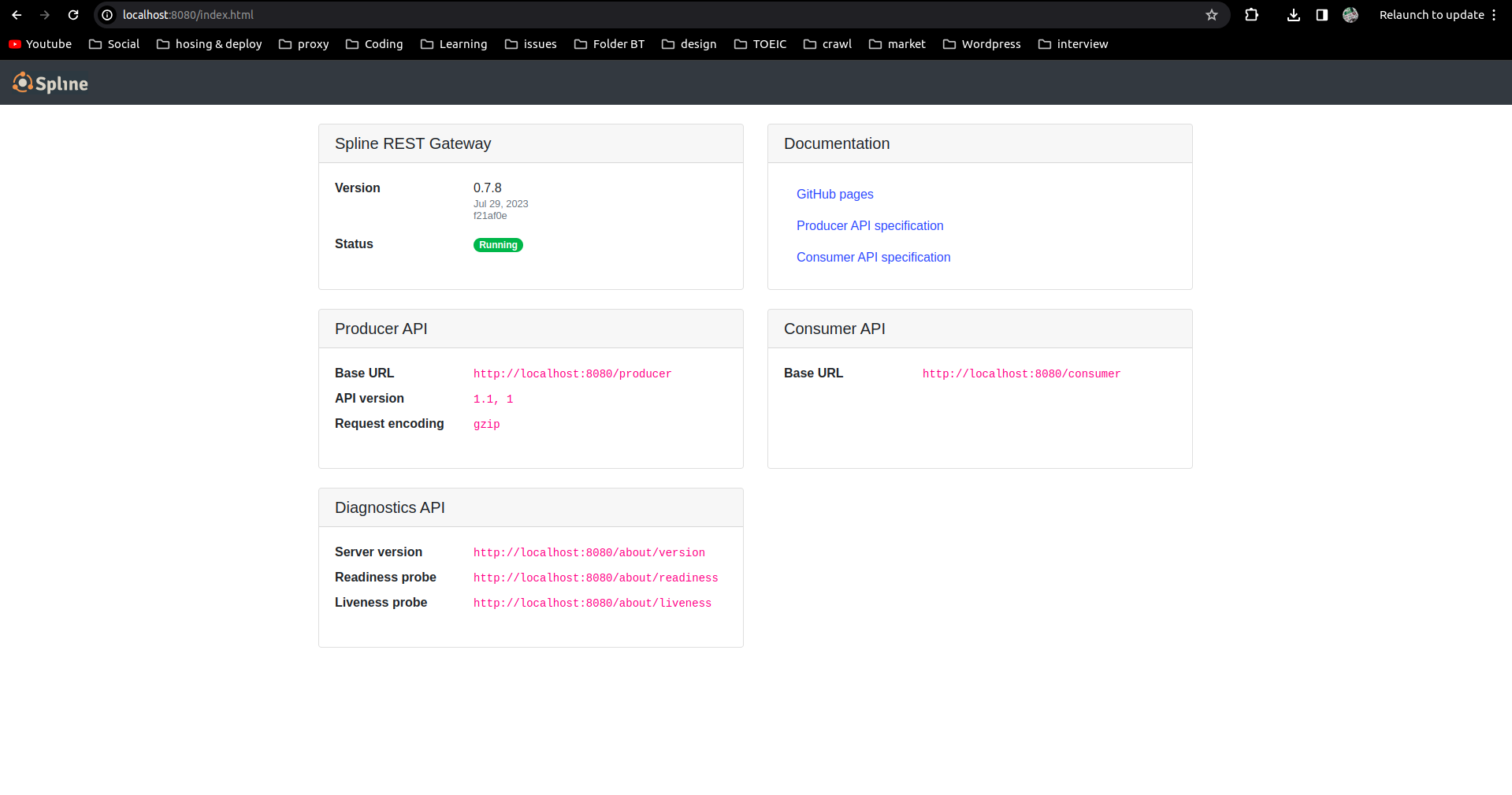
Chờ một lúc để Spline khởi động và kiểm tra 2 cổng 8888 (cổng Spline Server) và 9999 (cổng Spline UI):
Thu thập Data Lineage Spark Job qua Spline
Cầu hình Spark
Cấu hình Spark Agent
Để Spline có thể thu thập dữ liệu từ Spark cần cấu hình Spline Agent cho Spark để mỗi lần job được thực thi Spline Agent có thể thu thập thông tin về data lineage để gửi vể Spline Server.
- Thêm cấu hình vào file
$SPARK_HOME/conf/spark-defaults.conf:
1
2
spark.sql.queryExecutionListeners za.co.absa.spline.harvester.listener.SplineQueryExecutionListener
spark.spline.producer.url http://localhost:8888/producer
- Nếu không muốn cấu hình trong
spark-defaults.confthì có thể thêm cấu hình tham số cho mỗi lần chạypyspark,spark-shell,spark-submit:
1
2
3
pyspark \
--conf "spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener" \
--conf "spark.spline.producer.url=http://localhost:8888/producer"
Cấu hình thư viện
Tải thư viện
spark-3.0-spline-agent-bundle_2.12:2.0.0và đặt vào trong thư mục$SPARK_HOME/jars: spark-3.0-spline-agent-bundle_2.12:2.0.0Nếu không muốn tải về thêm thư viện thủ công như trên thì có thể thêm cấu hình tham số sau cho mỗi lân chạy
spark-shell,pyspark,spark-submit:
1
2
pyspark \
--packages za.co.absa.spline.agent.spark:spark-3.0-spline-agent-bundle_2.12:2.0.0
Chương trình đọc ghi đơn giản với pyspark
Việc chạy với pyspark, spark-submit hay spark-shell đều là như nhau, trong ví dụ này mình sẽ thử với pyspark để xem Spline vẽ data lineage của luồng dữ liệu như thế nào.
1
2
3
4
5
6
7
8
9
10
11
# Import SparkSession
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.master("spark://PC0628:7077") \
.appName("Spark SQL ananytic Tiki data") \
.getOrCreate()
data = spark.read.parquet("hdfs://localhost:9001/tiki/*")
data.write.parquet('hdfs://localhost:9001/output')
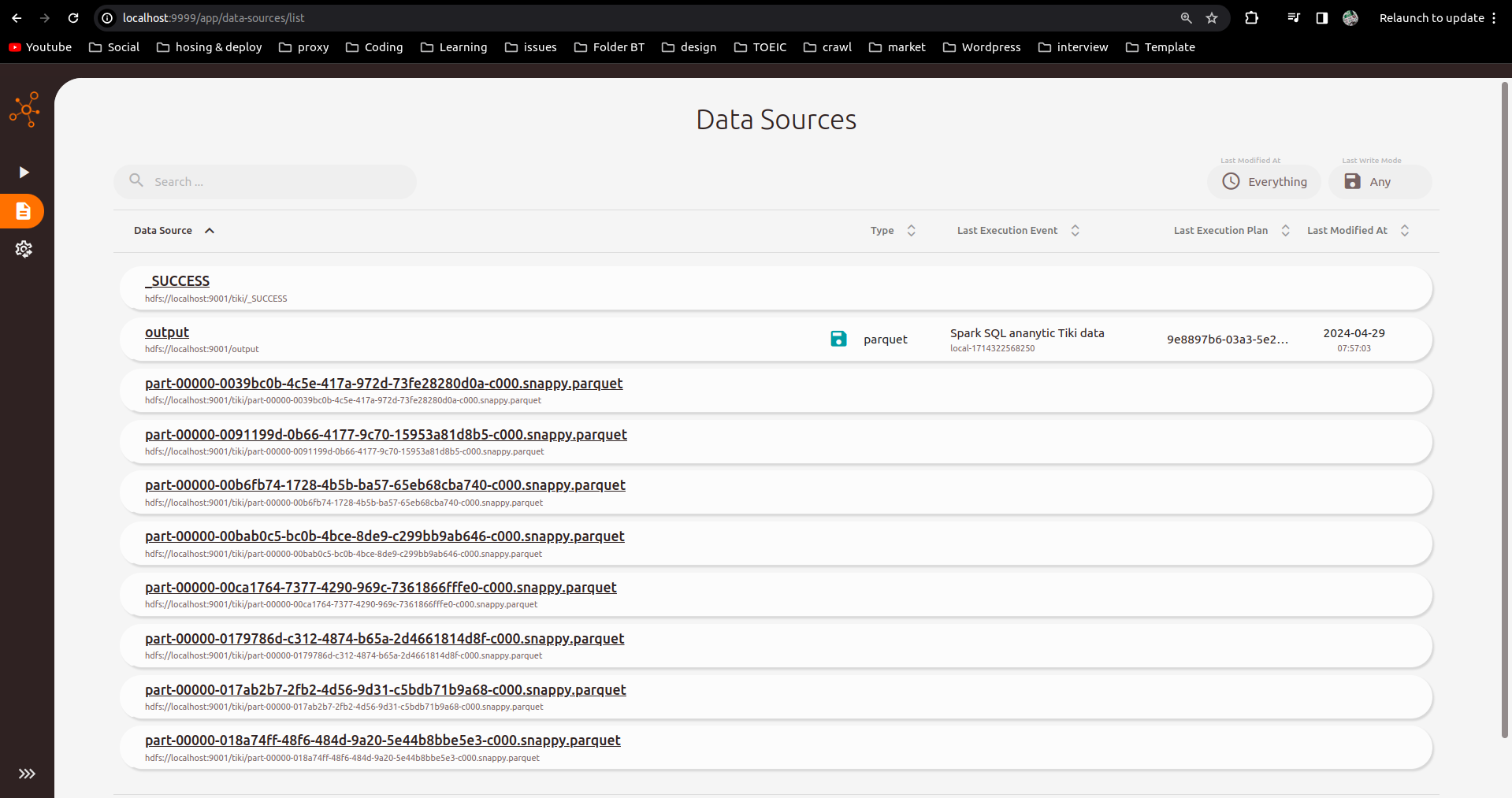
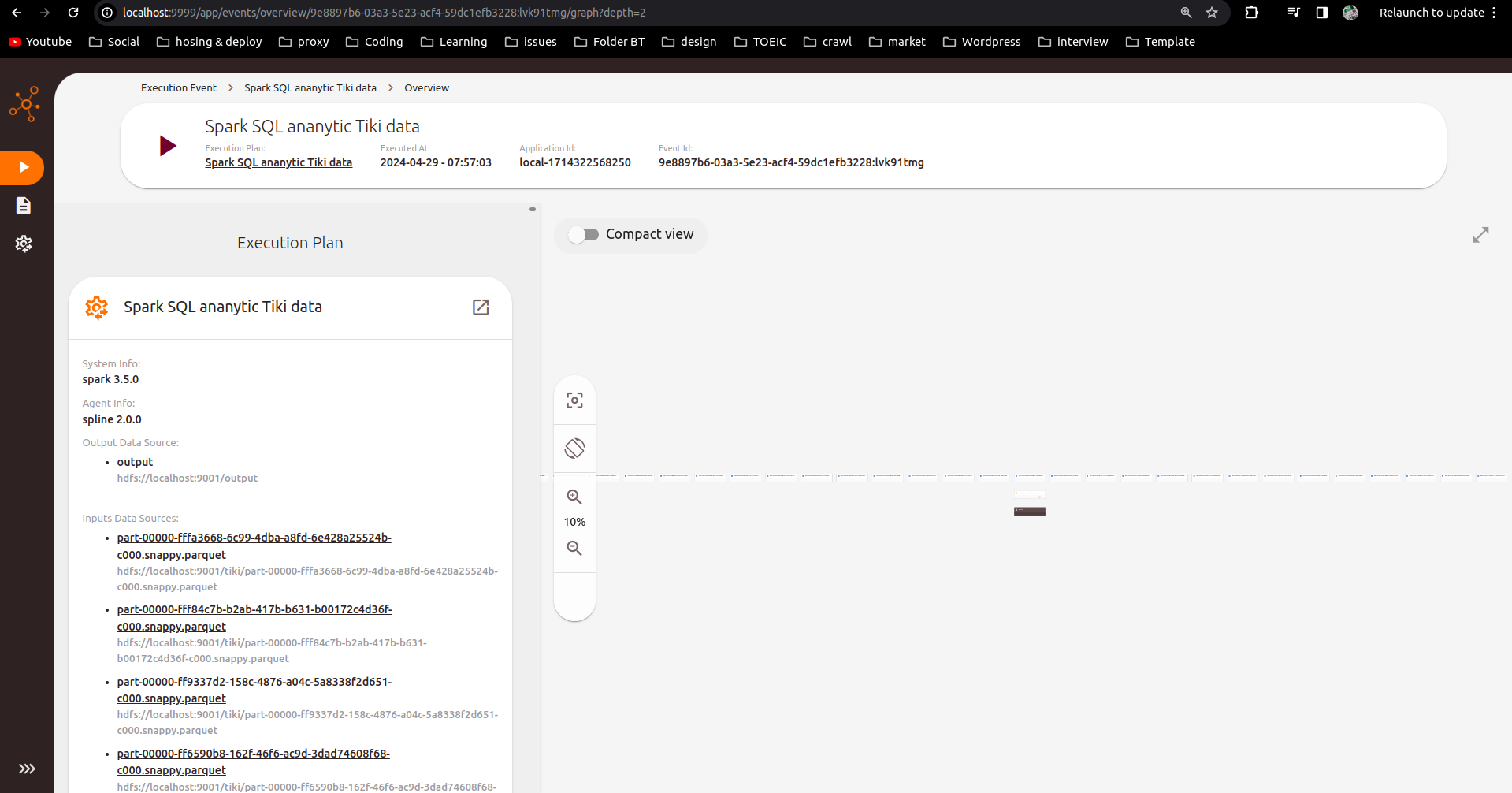
Kiểm tra kết quả data lineage
Kiểm tra kết quả trên cổng giao diện của Spline UI localhost:9999:
Tham khảo: https://absaoss.github.io/spline/