
Tổng quan về Apache Spark
Spark ban đầu được Matei Zaharia bắt đầu tại AMPLab của UC Berkeley vào năm 2009 và được mở nguồn vào năm 2010 theo giấy phép BSD. Vào năm 2013, dự án đã được quyên góp cho Apache Software Foundation và chuyển giấy phép sang Apache 2.0. Vào tháng 2 năm 2014, Spark trở thành Dự án Apache Cấp cao nhất.
Tại sao Spark lại ra đời?
- Trước khi Spark ra đời, Hadoop đang là một công cụ mạnh mẽ và phổ biến, tuy nhiên Hadoop có những hạn chế nhất định và Spark ra đời để cải thiện các hạn chế đó.
- Mô hình lập trình của MapReduce hiện tại dựa trên acyclic data flow (dòng dữ liệu tuần hoàn) từ một bộ nhớ ổn định tới một bộ nhớ ổn định, nôm na là Hadoop nhận đầu vào từ một bộ nhớ ổn định và sau mỗi Task hoàn thành kết quả được lưu lại trên một bộ nhớ ổn định. Điều này khiến cho việc nếu muốn dùng lại dữ liệu đó chúng ta phải đọc lại dữ liệu từ bộ nhớ
- Machine learning phát triển dẫn tới việc khi chúng ta chạy một thuật toán machine learning trên Hadoop sẽ mất thời gian. Vì các thuật toán Machine learning đa số là các thuật toán thuộc dạng Iterative algorithms (lặp đi lặp lại) nên việc sau mỗi lân lặp dữ liệu được lưu tại một bộ nhớ ổn định và được đọc lại để làm đầu vào cho vòng lặp tiếp theo là tốn rất nhiều thời gian
Mục tiêu của Spark:
- Tối ưu hóa để xử lý lặp đi lặp lại đối với các bài toán học máy
- Phân tích dữ liệu tương tác trong khi vẫn giữ được khả năng mở rộng và khả năng chịu lỗi của Hadoop MapReduce
- Xử lý dữ liệu tinh vi
- Xử lý dữ liệu streaming với độ trễ thấp
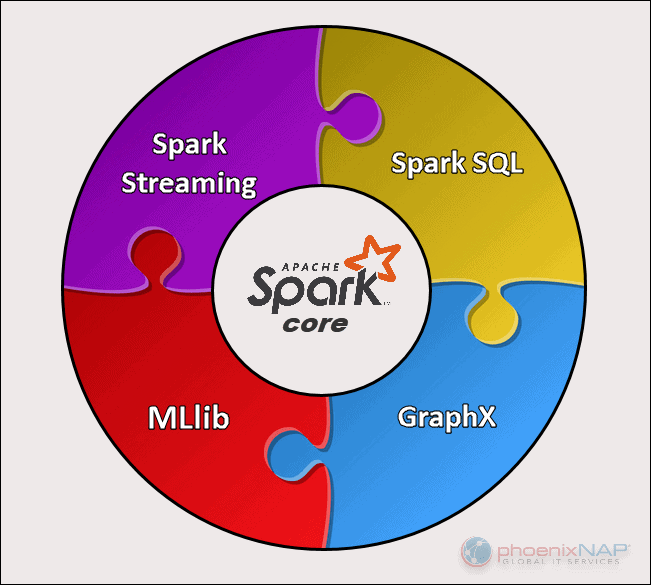
Có 5 thành phần chính của Spark:
 (Ảnh: phoenixnap)
(Ảnh: phoenixnap)
- Spark core: là các hàm, thư viện cơ sở, cung cấp các chức năng cần thiết như lập lịch, I/O,…
- Spark streaming: là thành phần hỗ trợ xử lý các dữ liệu streams, dữ liệu đầu vào có thể là từ nhiều nguồn như Socket, Kafka, Flume,…
- Spark SQL: là một mô-đun Spark để xử lý dữ liệu có cấu trúc. Nó cung cấp một chương trình trừu tượng gọi là DataFrames và cũng có thể hoạt động như một công cụ truy vấn SQL phân tán
- Spark MLib: cung cấp các thư viện hỗ trợ nhiều thuật toán machine learning
- Spark GraphX: là API Spark dành cho đồ thị và tính toán song song đồ thị
Spark vs Hadoop
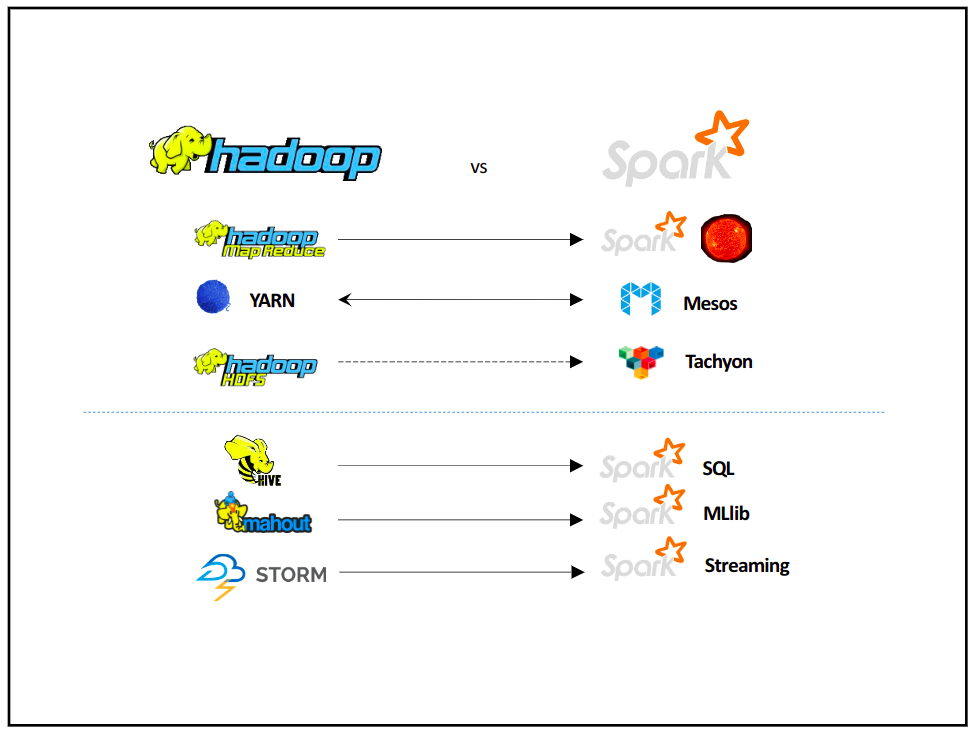
Để so sánh về Hadoop và Spark thì quả thật phải là một bài viết rất là dài, trong phần này mình sẽ tóm gọn lại những ý chính về sự khác biệt giữa Hadoop và Spark.
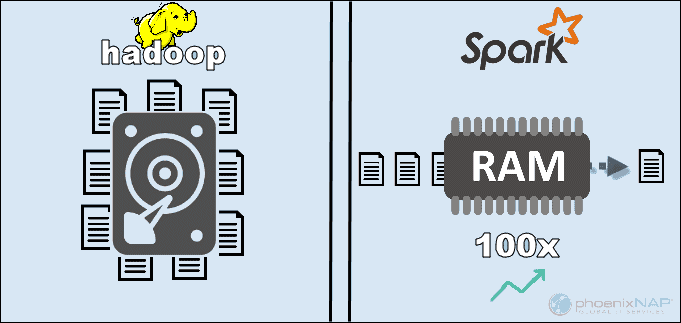
Tốc độ (Performance)
 (Ảnh: phoenixnap)
(Ảnh: phoenixnap)
Như mình đã nói trong phần mục tiêu của Spark, Spark ra đời để giải quyết vấn đề khi phải I/O nhiều của Hadoop. Vì thế Spark nhanh hơn rất nhiều so với Hadoop. Theo Apache, Spark dường như nhanh hơn 100 lần khi sử dụng RAM để tính toán so với Hadoop MapReduce.
Chi phí (Cost)
Hadoop và Spark đều là open source và miễn phí vậy nên chi phí cài đặt cả hai là bằng 0. Sự khác biệt về mặt chi phí giữa Hadoop và Spark gồm những chi phí như phần cứng, bảo trì, cài đặt, chi phí thuê chuyên gia.
Hadoop yêu cầu về phần cứng trong khi Spark yêu cầu về RAM, vì thế chi phí phần cứng để xây dựng các cụm Spark là đắt đỏ hơn Hadoop. Thêm nữa, Spark là một công nghệ mới, ra sau nên các chuyên gia về Spark sẽ ít và đắt đỏ hơn Hadoop.
Xử lý dữ liệu (Data processing)
Trong cả hai nền tảng, việc xử lý dữ liệu diễn ra trong môi trường phân tán. Trong khi Hadoop thích hợp cho xử lý hàng loạt và xử lý dữ liệu tuyến tính, Spark lại lý tưởng để xử lý thời gian thực cũng như xử lý các luồng dữ liệu phi cấu trúc trực tiếp.
Bảo mật (Security)
Hadoop có các tính năng bảo mật tốt hơn trong khi bảo mật của Spark đang trong giai đoạn sơ khai.
Machine learning
Spark thực hiện các phép tính ML trong bộ nhớ nên cho phép việc lặp đi lặp lại mà không mất quá nhiều thời gian như Hadoop. Spark MLib gồm các bộ thư viện học máy giúp cho việc xử lý các bài toán học máy dễ dàng hơn.
Sử dụng
Hadoop dựa trên Java. Hai ngôn ngữ chính để viết mã MapReduce là Java hoặc Python. Hadoop không có chế độ tương tác để hỗ trợ người dùng. Tuy nhiên, nó tích hợp với các công cụ Pig và Hive để tạo điều kiện thuận lợi cho việc viết các chương trình MapReduce phức tạp.
Với Spark bạn có nhiều lựa chọn hơn vì Spark cung cấp ra ngoài các API hỗ trợ cho nhiều ngôn ngữ. Spark còn chiến thắng ở phần dễ sử dụng với chế độ tương tác của nó. Chúng ta có thể sử dụng Spark shell để phân tích dữ liệu tương tác với Scala hoặc Python. Shell cung cấp phản hồi tức thì cho các truy vấn, giúp Spark dễ sử dụng hơn Hadoop MapReduce.
Hadoop hay Spark?
Qua những ưu, nhược điểm mà mình đã nói về Hadoop, Spark ở bên trên thì Spark hay Hadoop là lựa chọn cho bigdata bây giờ? Rõ ràng là Spark có phần nhỉnh hơn đôi chút, tuy nhiên chúng không tạo ra để cạnh tranh với nhau mà là bổ sung cho nhau.
Và câu trả lời cho “Hadoop hay Spark?” là không gì cả, Hadoop và Spark phải đồng hành với nhau. Chúng ta đều thấy Spark mặc dù có những ưu điểm hơn về xử lý tuy nhiên có rất nhiều thứ mà Spark chưa thể thay thế được với Hadoop.
Bằng cách kết hợp cả hai, Spark có thể tận dụng các tính năng mà nó còn thiếu, chẳng hạn như hệ thống tệp. Hadoop lưu trữ một lượng lớn dữ liệu bằng cách sử dụng phần cứng giá cả phải chăng và sau đó thực hiện phân tích, trong khi Spark mang đến quá trình xử lý theo thời gian thực để xử lý dữ liệu đến.
Spark cũng có thể tận dụng các lợi ích về bảo mật và quản lý tài nguyên của Hadoop. Với YARN, việc phân cụm Spark và quản lý dữ liệu dễ dàng hơn nhiều. Bạn có thể tự động chạy khối lượng công việc Spark bằng bất kỳ tài nguyên nào có sẵn.
Tham khảo: https://phoenixnap.com/, https://spark.apache.org