
Hadoop Distributed File System (HDFS) là hệ thống lưu trữ phân tán được thiết kế để chạy trên các phần cứng thông dụng. HDFS có khả năng chịu lỗi cao được triển khai sử dụng các phần cứng giá rẻ. HDFS cung cấp khả năng truy cập thông lượng cao vào dữ liệu ứng dụng vì thế nó rất phù hợp với ứng dụng có tập dữ liệu lớn.
Mục tiêu của HDFS
Tiết kiệm chi phí cho việc lưu trữ dữ liệu lớn: có thể lưu trữ dữ liệu megabytes đến petabytes, ở dạng có cấu trúc hay không có cấu trúc
Dữ liệu có độ tin cậy cao và có khả năng khắc phục lỗi: Dữ liệu lưu trữ trong HDFS được nhân bản thành nhiều phiên bản và được lưu tại các DataNode khác nhau, khi có 1 máy bị lỗi thì vẫn còn dữ liệu được lưu tại DataNode khác
Tính chính xác cao: Dữ liệu lưu trữ trong HDFS thường xuyên được kiểm tra bằng mã checksum được tính trong quá trình ghi file, nếu có lỗi xảy ra sẽ được khôi phục bằng các bản sao
Khả năng mở rộng: có thể tăng hàng trăm node trong một cluster
Có throughput cao: tốc độ xử lý truy nhập dữ liệu cao
Data Locality: xử lý dữ liệu tại chỗ
HDFS Architecture
Theo dõi hình vẽ dưới để xem tổng quát về kiến trúc của HDFS:
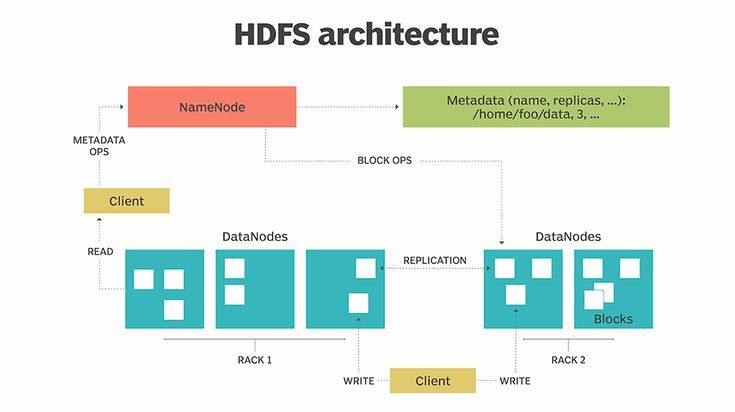
Với HDFS, dữ liệu được ghi trên 1 máy chủ và có thể đọc lại nhiều lần sau đó tại bất cứ máy chủ khác trong cụm HDFS. HDFS bao gồm 1 Namenode chính và nhiều Datanode kết nối lại thành một cụm (cluster).
Namenode
HDFS chỉ bao gồm duy nhất 1 namenode được gọi là master node thực hiện các nhiệm vụ:
Lưu trữ metadata của dữ liệu thực tế (tên, đường dẫn, blocks id, cấu hình datanode vị trí blocks,…)
Quản lý không gian tên của hệ thống file ( ánh xạ các file name với các blocks, ánh xạ các block vào các datanode)
Quản lý cấu hình của cụm
Chỉ định công việc cho datanode
Datanode
Chức năng của Datanode:
- Lưu trữ dữ liệu thực tế
- Trực tiếp thực hiện và xử lý công việc ( đọc/ghi dữ liệu)
Secondary Namenode
Secondary Namenode là một node phụ chạy cùng với Namenode, nhìn tên gọi nhiều người nhầm tưởng rằng nó để backup cho Namenode tuy nhiên không phải vậy, Secondary Namenode như là một trợ lý đắc lực của Namenode, có vai trò và nhiệm vụ rõ ràng:
Nó thường xuyên đọc các file, các metadata được lưu trên RAM của datanode và ghi vào ổ cứng
Nó liên đọc nội dung trong Editlogs và cập nhật vào FsImage, để chuẩn bị cho lần khởi động tiếp theo của namenode
Nó liên tục kiểm tra tính chính xác của các tệp tin lưu trên các datanode
Cơ chế heartbeat
Heartbeat là cách liên lạc hay là cách để datanode cho namenode biết là nó còn sống. Định kì datanode sẽ gửi một heartbeat về cho namenode để namenode biết là datanode đó còn hoạt động. Nếu datanode không gửi heartbeat về cho namenode thì namenode coi rằng node đó đã hỏng và không thể thực hiện nhiệm vụ được giao. Namenode sẽ phân công task đó cho một datanode khác.
Rack
Theo thứ tự giảm dần từ cao xuống thấp thì ta có Rack > Node > Block. Rack là một cụm datanode cùng một đầu mạng, bao gồm các máy vật lí (tương đương một server hay 1 node ) cùng kết nối chung 1 switch.
Blocks
Blocks là một đơn vị lưu trữ của HDFS, các data được đưa vào HDFS sẽ được chia thành các block có các kích thước cố định (nếu không cấu hình thì mặc định nó là 128MB).
Vấn đề gì xảy ra nếu lưu trữ các file nhỏ trên HDFS?
Câu trả lời: HDFS sẽ không tốt khi xử lý một lượng lớn các file nhỏ. Mỗi dữ liệu lưu trữ trên HDFS được đại diện bằng 1 blocks với kích thước là 128MB, vậy nếu lưu trữ lượng lớn file nhỏ thì sẽ cần 1 lượng lớn các block để lưu chữ chúng và mỗi block chúng ta chỉ cần dùng tới 1 ít và còn thừa rất nhiều dung lượng gây ra sự lãng phí. Chúng ta cũng có thể thấy là block size của hệ thống file ở các hệ điều hành tiêu biểu như linux là 4KB là rất bé so với 128MB.
Hoạt động
Sau đây mình sẽ trình bày nguyên lí chung của đọc ghi dữ liệu trên HDFS:
Write data
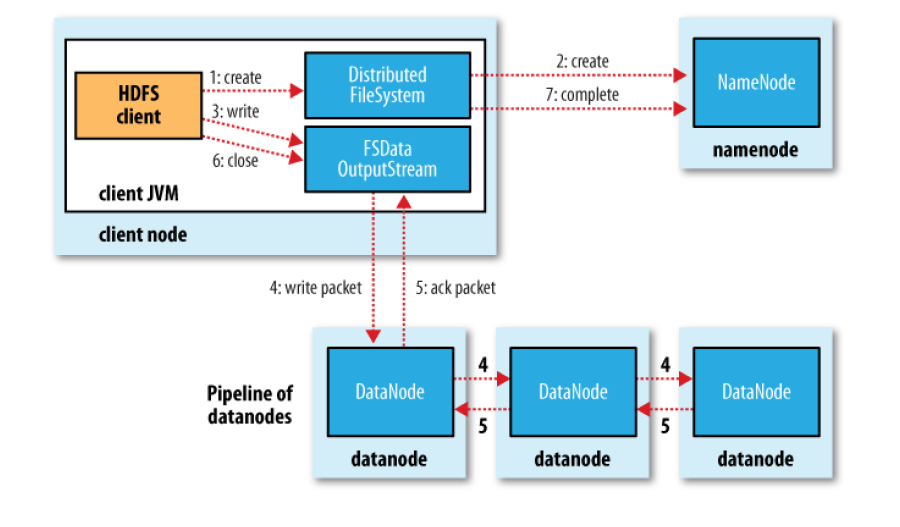
Theo trình tự trong hình ta có các bước write dữ liệu như sau:
Client gửi yêu cầu tạo file ở DistributedFileSystem APIs
DistributedFileSystem yêu cầu tạo file ở NameNode.NameNode kiểm tra quyền của client và kiểm tra file mới có tồn tại hay không…
DistributedFileSystem return FSDataOutPutStream cho client để ghi dữ liệu. FSDataOutputStream chứa DFSOutputStream, nó dùng để xử lý tương tác với NameNode và DataNode. Khi client ghi dữ liệu, DFSOutputStream chia dữ liệu thành các packet và đẩy nó vào hàng đợi DataQueue. DataStreamer sẽ nói với NameNode để phân bổ các block vào các datanode để lưu trữ các bản sao
Các DataNode tạo thành pipeline, số datanode bằng số bản sao của file. DataStream gửi packet tới DataNode đầu tiên trong pipeline, datanode này sẽ chuyển tiếp packet lần lượt tới các Datanode trong pipeline
DFSOutputStream có Ack Queue để duy trì các packet chưa được xác nhận bởi các DataNode. Packet ra khỏi ackqueue khi nhận được xác nhận từ tất cả các DataNode
Client gọi close() để kết thúc ghi dữ liệu, các packet còn lại được đẩy vào pipeline
Sau khi toàn bộ các packet được ghi vào các DataNode, thông báo hoàn thành ghi file
Đó là toàn bộ những gì diễn ra ở đằng sau, còn đây là ví dụ một trong những lênh thao tác ghi trên hdfs:
1
hdfs dfs -put <path_on_your_computer> <path_on_hadoop>
Trong quá trình thực tế hầu như sẽ không làm việc trực tiếp với hệ thống file system của hadoop(HDFS) bằng câu lệnh, mà ta thường đọc, ghi qua spark, ví dụ:
1
dataFrame.write.save("<path_on_hadoop>")
Read data
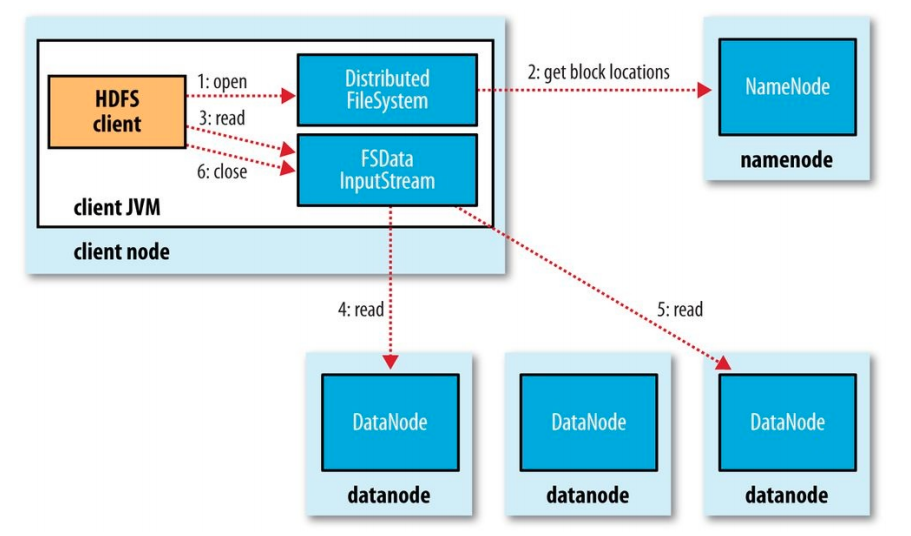
Để mở file, client gọi phương thức open ở FileSystemObject
DistributedFileSystem gọi Name để lấy vị trí của blocks của file. NameNode trả về địa chỉ của các DataNode chứa bản sao của block đó
Sau khi nhận được địa chỉ của các NameNode, Một đối tượng FSDataInputStream được trả về cho client. FSDataInputStream chứa DFSInputStream. DFSInputStream quản lý I/O của DataNode và NameNode
Client gọi phương thức read() ở FSDataInputStream, DFSInputStream kết nối với DataNode gần nhất để đọc block đầu tiên của file. Phương thức read() được lặp đi lặp lại nhiều lần cho đến cuối block
Sau khi đọc xong, DFSInputStream ngắt kết nối và xác định DataNode cho block tiếp theo. Khi DFSInputStream đọc file, nếu có lỗi xảy ra nó sẽ chuyển sang DataNode khác gần nhất có chứa block đó
Khi client đọc xong file, gọi close()