
Apache Nifi is used to automate and control data flows between systems. It provides us with a web-based interface that can collect, process, and analyze data.
NiFi is known for its ability to build automated data transfer flows between systems. Especially it supports many different types of sources and destinations such as: file systems, relational databases, non-relational databases,… In addition, Nifi will support data operations such as filtering, editing, adding and removing content.
Main Components
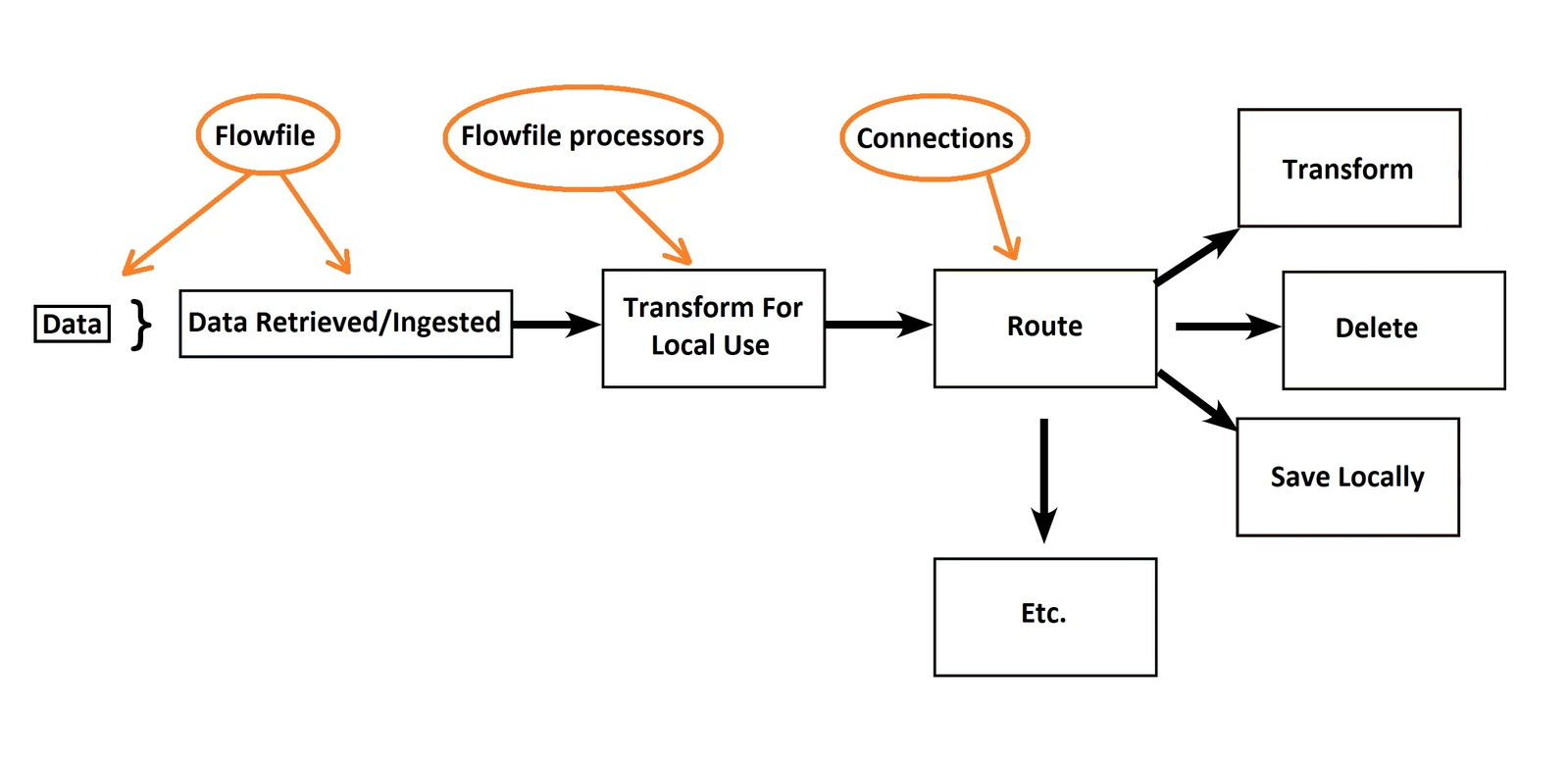
Flowfile
Represents the data unit being executed in the flow, for example a text record, an image file… consists of 2 parts:
- Content: the data it represents
- Attribute: properties of the flow file (key-value)
Flowfile Processor
These are the things that perform work in Nifi, inside it already contains code to execute tasks in cases with input and output. Processing blocks generate flowfiles. Processors operate in parallel with each other
Connection
Connection plays the role of connecting between processors. In addition, it is also a queue containing unprocessed flowfiles:
- Determines how long flowfiles exist in the queue
- Distributes flowfiles to nodes in the cluster (load balancing)
- Determines the frequency at which flowfiles are released to the system
System Architecture
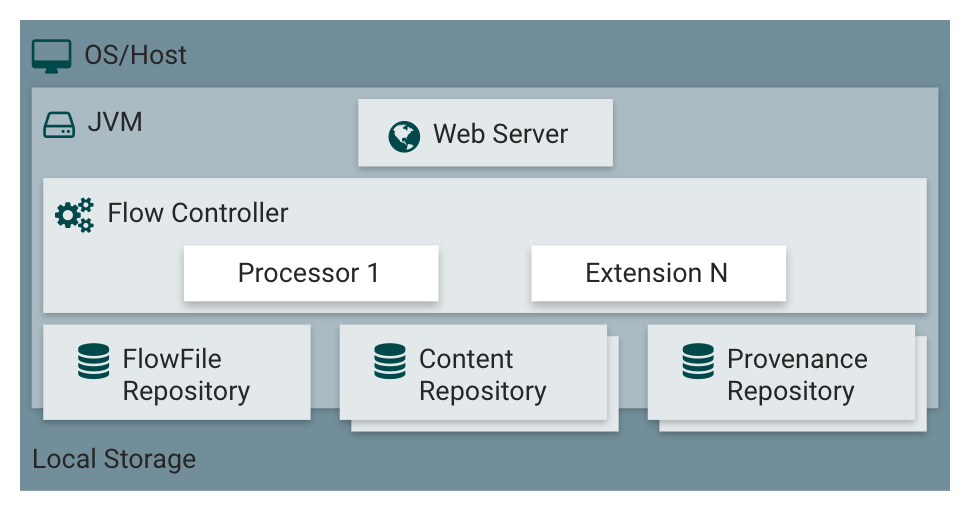
- Web server: provides interface for users to perform operations
- Flow Controller: provides resources for system operation
- Extensions: Includes components that build data flows in Nifi: processors responsible for processing and routing; Logs, Controller services contain functions used by other extensions
- Flowfile repository: Only stores metadata of flowfiles because flowfiles already store data
- Content repository: Stores actual data being processed in the flow. Nifi stores all versions of data before and after processing
- Provenance repository: Stores the entire history of flowfiles
Outstanding Features of Nifi
Data Source Management Capability
- Ensures safety: Each data unit in the flow will be stored as a flowfile object. It will record information about which data block is being processed where, moving where… Provenance Repo is used to store flowfiles to help us trace
- Data Buffering: Solves the problem of data write speed being faster than data read speed between two processing blocks. This data will be stored in RAM, if it exceeds a threshold, it will be stored on the hard drive
- Priority setting: In data processing, there is data that we must process with priority
- Trade-off between speed and fault tolerance: Nifi supports settings to balance these two factors
Easy to Use
- Nifi supports UI for building data flows
- Reusability when we can save data flows as a template
- Visual history tracking
Horizontal Scaling
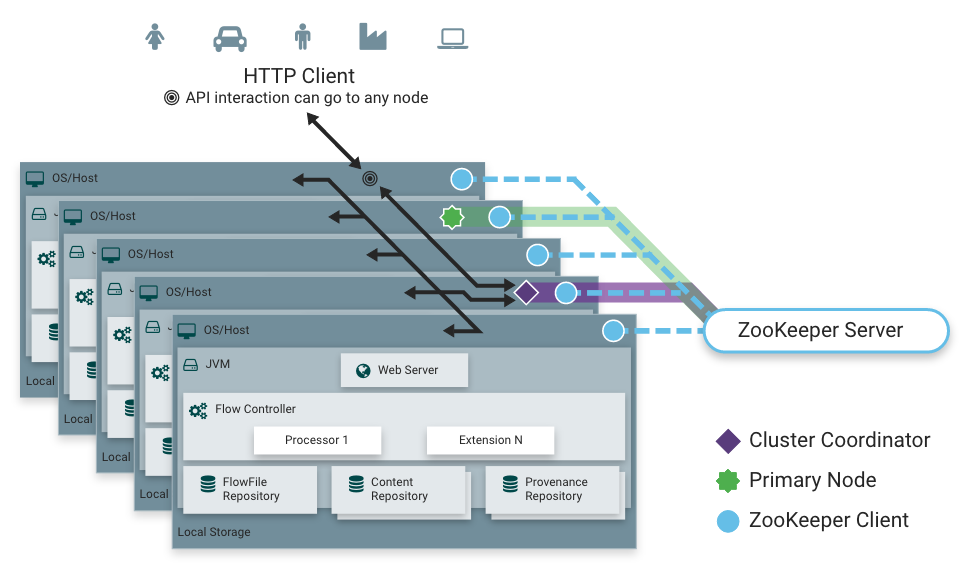
Suppose with Nifi running on only 1 server that cannot handle it, what do we do -> run the same dataflow on multiple servers. Administrators do not need to modify all dataflows on different servers but only need to change once and it will automatically copy to other servers.
Nifi clusters follow the Zero-master principle, meaning all servers have the same work but process different data. A Node will be selected as the cluster manager (Cluster Coordinator) through Zookeeper. All nodes in the cluster will send status to this node, and this node is responsible for disconnecting nodes that do not send status within a certain period of time. In addition, this Node will be responsible for new nodes joining the cluster. New nodes must first connect to this node so data can be updated.