
Wordcount cũng là một chương trình kinh điển khi nhắc tới Spark, một phần cũng là để so sánh hiệu năng với chính Hadoop MapReduce. Trong bài viết này mình sẽ hướng dẫn mọi người tạo và chạy chương trình Wordcount với spark-submit sử dụng Java và spark-shell sử dụng Scala.
Khởi động HDFS và Spark
Với Spark hay Hadoop thì các bạn đều có thể chạy với file ở trên local, tuy nhiên để cho thực tế thì chúng ta sẽ sử dụng cả đầu vào và đầu ra đều đặt trên HDFS, nếu máy bạn chưa có HDFS thì hãy cài Single Node để làm quen nha: Cài đặt và triển khai Hadoop Single Node
Vào thư mục chứa Hadoop và khởi động HDFS lên với câu lệnh:
1
sbin/start-dfs.sh
Vào thư mục chứa Spark và khởi động Spark lên với câu lệnh:
1
sbin/start-all.sh
Kiểm tra các daemon đã khởi động bằng câu lệnh jps:
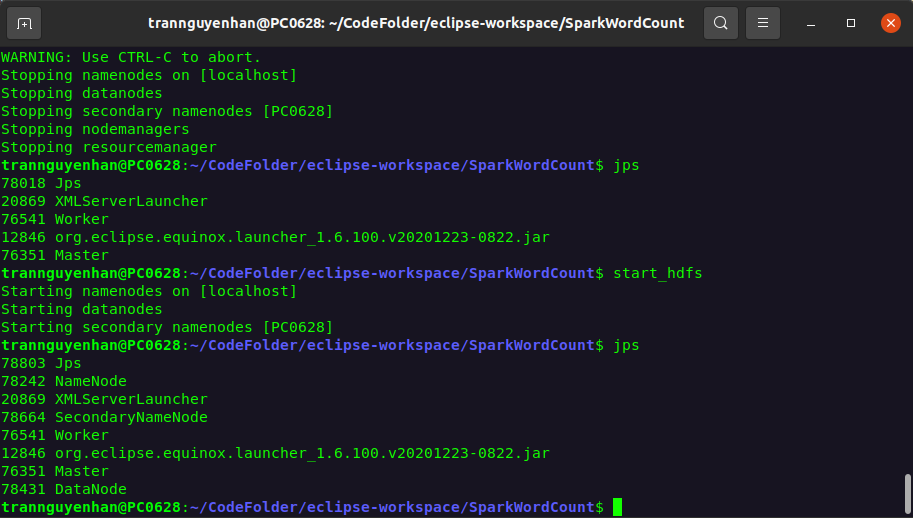
Các bạn chỉ cần quan tâm tới các daemon NameNode, SecondaryNameNode, DataNode, Worker, Master đã có chưa? còn mấy cái le ve khác kệ nó.
Truy cập vào cổng 8080 của máy master, máy mình cài Spark Single Node nên mình truy cập thông qua địa chỉ http://localhost:8080/ và ghi nhớ lại địa chỉ Spark Master của bạn:
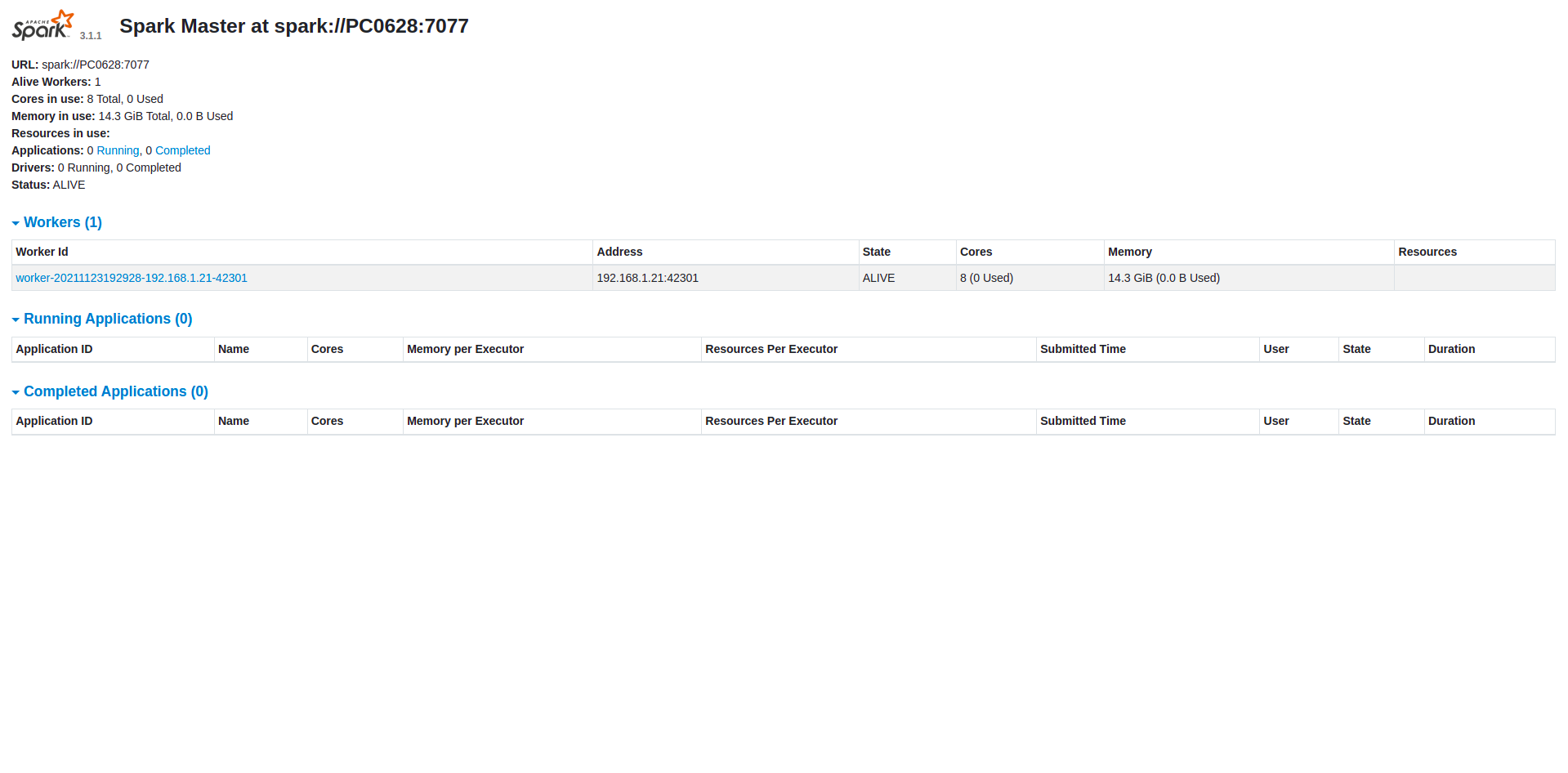
Giống như trên máy mình thì nó chính là địa chỉ spark://PC0628:7077.
Wordcount với spark-submit sử dụng Java
Bước 1
Tạo một project maven mới với IDE mà bạn dùng và thêm vào đó dependency spark-core như sau:
1
2
3
4
5
6
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
Code spark thì ngắn gọn hơn so với Hadoop MapReduce rất nhiều, các bạn tạo một package là spark.main và tạo một class Main trong package đó:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
package spark.main;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class Main {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("spark://PC0628:7077").setAppName("Spark Word Count");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<String> textFile = sc.textFile("hdfs://localhost:9000/input/input-1.txt");
JavaPairRDD<String, Integer> result = textFile.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a,b) -> (a+b));
result.saveAsTextFile("hdfs://localhost:9000/output/result");
}
}
}
- Tại phần
setMasterhãy thay lại thành địa chỉ Spark Master của bạn
Chú ý: nếu chưa biết Spark-RDD là gì thì bạn có thể xem lại bài viết về Spark-RDD TẠI ĐÂY nha.
Bước 2
Để chạy project với spark-submit thì chúng ta phải build project thành file .jar, sử dụng mvn để build project thành file .jar như sau:
1
mvn clean package
Kết quả hiển thị BUILD SUCCESS là bạn đã build thành công file .jar cho project của bạn, file .jar sinh ra được đặt trong thư mục target:
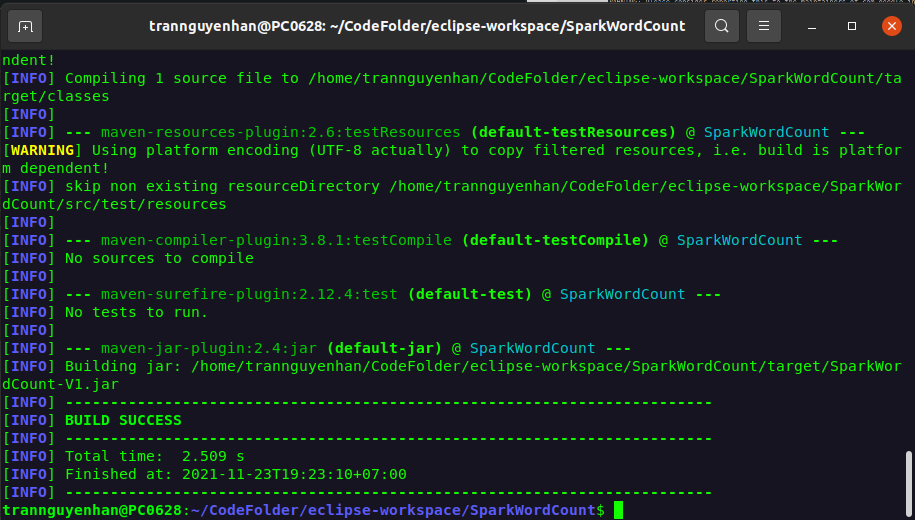
Bước 3
Chạy file .jar vừa sinh ra với spark-submit bằng câu lệnh:
1
spark-submit --class spark.main.Main target/SparkWordCount-V1.jar
Sau khi chạy xong, nếu không có bất kì một log ERROR nào thì chương trình của bạn đã chạy thành công:
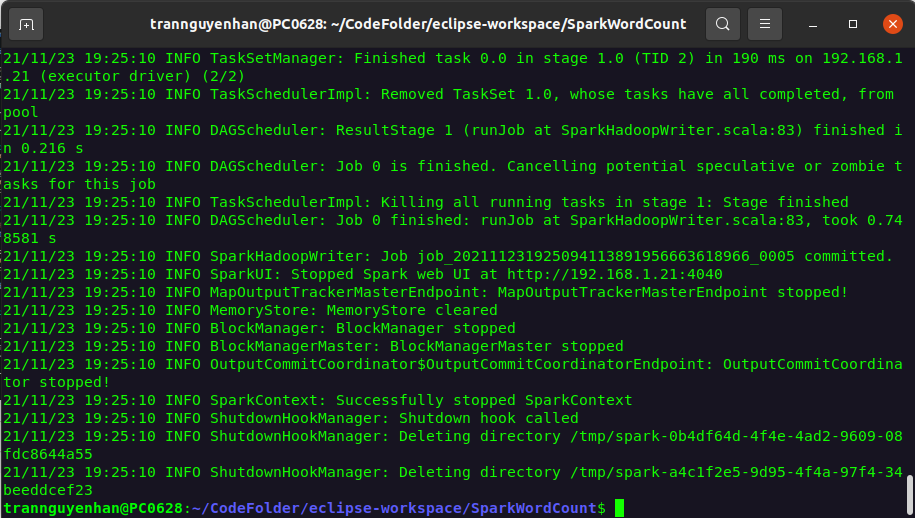
Để kiểm tra kết quả đã sinh ra trên HDFS sử dụng câu lệnh:
1
hdfs dfs -cat /output/result/part-00000
Kết quả sẽ là từng cặp từ với tần suất xuất hiện của chúng:
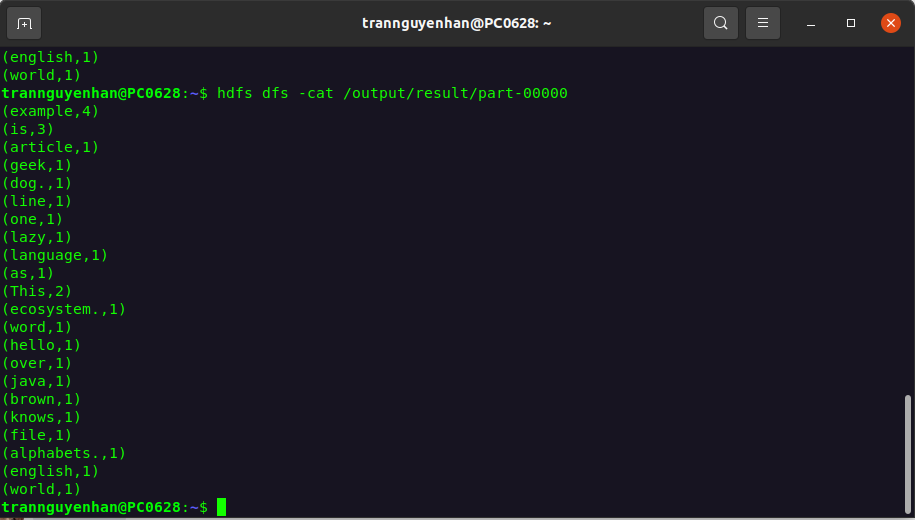
Để xem thông tin của job chạy vừa rồi các bạn có thể quay lại cổng UI của Spark tại địa chỉ http://localhost:8080/, tại phần Completed Applications sẽ có danh sách các job được hoàn thành, bấm vào từng job để xem chi tiết.
Wordcount với spark-shell sử dụng Scala
Với Java việc build file .jar sau đó submit có thể các bước hơi phức tạp và tốn thời gian thì chúng ta có thể thử sử dụng spark-shell, spark-shell cung cấp một giao diện tương tác trực tiếp, kết quả trả về ngay sau mỗi câu lệnh và sử dụng ngôn ngữ là Scala.
Bước 1
Mở spark-shell tại địa chỉ của Spark Master với câu lệnh sau:
1
spark-shell --master spark://PC0628:7077
Giao diện spark-shell sau khi mở sẽ giống như hình dưới đây:
Ngoài ra khi các bạn truy cập vào cổng UI của Spark http://localhost:8080/ thì sẽ thấy có 1 job đang chạy ở phần Running Applications với name do chúng ta chưa đặt nên sẽ có name mặc định là Spark shell.
Bước 2
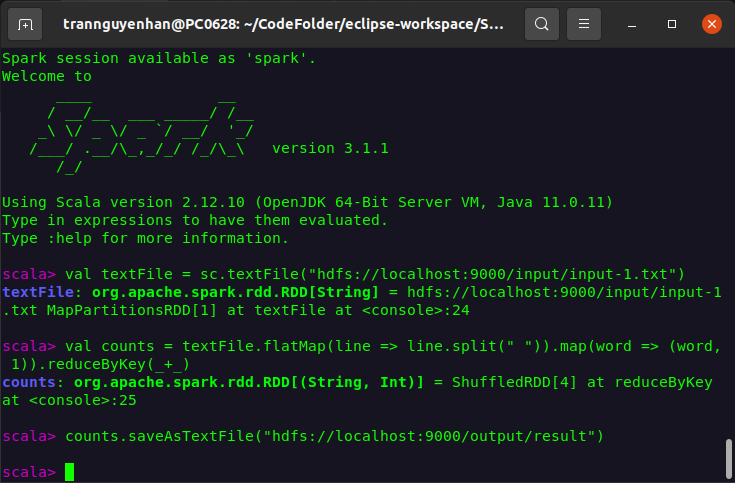
Viết chương trình Word Count trực tiếp trên spark-shell:
1
2
3
4
5
val textFile = sc.textFile("hdfs://localhost:9000/input/input-1.txt")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://localhost:9000/output/result")
- Do
sclà một biến đại diện choSparkContextđã được khai báo mặc định khi chúng ta mở spark-shell lên, vì vậy chúng ta không cần khai báo lại nữa - HDFS sẽ bắt lỗi và không cho phép chúng ta ghi vào một thư mục đã tồn tại, nên bạn nào bị mắc lỗi thư mục
output.resultđã tồn tại thì có thể xóa chúng đi bằng lệnhhdfs dfs -rm -r /output/resulthoặc chuyển output sang một đường dẫn khác
Bước 3
Kiểm tra kết quả trên HDFS và thông tin job đã chạy trên cổng UI của spark http://localhost:8080/ giống như những gì chúng ta đã làm với spark-submit.
Tham khảo: https://spark.apache.org/