
Spark MLlib là thư viện học máy của Spark được tạo ra với mục tiêu có thể giải quyết các bài toán ML một cách dễ dàng hơn. Mặc dùng các thư viện mà MLlib mang lại không phong phú bằng python với những sklearn, tensorflow, PyTorch,… Tuy nhiên MLlib hỗ trợ cho chương trình của bạn có thể chạy phân tán trên nhiều máy tại cụm Spark được thiết lập trước đó.
Ở mức cao, Spark MLlib cung cấp một số thư viện và công cụ như là:
- ML Algorithms: là các thư viện thuật toán được xây dựng sẵn như là các thuật toán classification, regresion, clustering hay collaborative filtering
- Featurization: trích xuất tính năng, chuyển đổi, giảm kích thước và lựa chọn
- Persistence: các thuật toán sau khi train có thể lưu và load lại một cách dễ dàng
- Utilities: xử lý dữ liệu, phân tích và thống kê,…
Trong bài viết lần này mình sẽ minh họa bài toán phân cụm với LDA bằng Spark MLlib và sử dụng Flask để viết API cho ứng dụng Spark MLlib này.
Theo ý kiến của riêng mình, với những thuật toán MLlib thì việc sử dụng các ngôn ngữ thông dịch và đặc biệt là Python sẽ hợp lý hơn vì sự hỗ trợ và cộng đồng mà nó mang lại, vì vậy không giống như những modules khác mình thích sử dụng Java thì với Spark MLlib mình lại ưa thích hơn việc sử dụng Python.
Chuẩn bị dữ liệu đầu vào
Dữ liệu đầu vào phải được quy định trước về định dạng và các trường để cho người làm dữ liệu và người làm mô hình có sự thống nhất, với Spark một số định dạng phổ biến được hỗ trợ đọc và ghi trực tiếp như là parquet, json, csv,… và chúng đều là những định dạng lưu trữ phổ biến và cực kì quen thuộc.
Trong bài ví dụ này chúng ta sẽ sử dụng định dạng dữ liệu csv với 3 trường dữ liệu đầu vào là title, content, date. Tuy nhiên, việc phân loại hiện tại chỉ sử dụng trường content, 2 trường title và date các bạn có thể mở rộng thêm để tăng tính chính xác cho mô hình bài toán.
Tiền xử lý
Dữ liệu trước khi đưa vào mô hình cũng phải được xử lý như là xóa đi những stopword, những dấu cách, dấu phẩy thừa, chuẩn hóa tất cả về dạng viết thường,…
Những công việc này các thư viện do Python cung cấp đã hỗ trợ rất tốt, nếu bạn đang làm bài toán với tiếng Anh thì có thể sử dụng ngay thư viện nltk, còn nếu sử dụng tiếng Việt thì chắc sẽ phải tự tạo kho từ điển stopword của riêng mình.
Với hàm tiền xử lý này, đầu vào sẽ nhận một RDD và sẽ trả ra 1 RDD đã được xử lý:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from nltk.corpus import stopwords
import re as re
# pre processing data
def preprocessing(rdd):
reviews = rdd.map(lambda x: x['Content']).filter(lambda x: x is not None)
StopWords = stopwords.words("english")
tokens = reviews.map(lambda document: document.strip().lower())
tokens = tokens.map(lambda document: re.split(" ", document))
tokens = tokens.map(lambda word: [x for x in word if x.isalpha()])
tokens = tokens.map(lambda word: [x for x in word if len(x) > 3])
tokens = tokens.map(lambda word: [x for x in word if x not in StopWords])
return tokens
Xây dựng mô hình phân cụm với LDA
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import os
import shutil
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
from pyspark.ml.clustering import LDA
from pyspark.ml.feature import CountVectorizer
from preprocessing import preprocessing
import constants
# init Spark Context
conf = SparkConf().setAppName("Spark ML").setMaster("local[2]")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
# read raw data
data = sqlContext.read.format("csv").options(header='true', inferSchema='true').load(os.path.realpath(constants.PATH))
rdd = data.rdd
# preprocessing data
tokens = preprocessing(rdd)
tokens = tokens.zipWithIndex()
df = sqlContext.createDataFrame(tokens, ["content", "index"])
# vector data
cv = CountVectorizer(inputCol="content", outputCol="features", vocabSize=500, minDF=3.0)
cvModel = cv.fit(df)
vectorizedToken = cvModel.transform(df)
# clustering
lda = LDA(k=constants.NUM_TOPICS, maxIter=constants.MAX_INTER)
model = lda.fit(vectorizedToken)
# get vocab
vocab = cvModel.vocabulary
topics = model.describeTopics()
topicsRdd = topics.rdd
# result
result = model.transform(vectorizedToken)
result.show()
# save model
if(os.path.isdir(constants.OUTPUT_PATH + "/Model_CountVectorizer")):
shutil.rmtree(constants.OUTPUT_PATH + "/Model_CountVectorizer")
cvModel.save(constants.OUTPUT_PATH + "/Model_CountVectorizer")
if(os.path.isdir(constants.OUTPUT_PATH + "/Model_LDA")):
shutil.rmtree(constants.OUTPUT_PATH + "/Model_LDA")
model.save(constants.OUTPUT_PATH + "/Model_LDA")
- Một số hằng số
constants.NUM_TOPICS,constants.OUTPUT_PATH,constants.OUTPUT_PATH,constants.MAX_INTERlà các hằng số đã được khai báo trước trong fileconstants.pyđể tiện cho việc sử dụng và thay đổi một cách dễ dàng - Trong phần minh họa code trên cũng đã có comment giải thích khá rõ cho từng phần nên mình cũng không giải thích gì thêm nữa
Sau khi save model chúng ta cũng có thể lôi ra sử dụng lại một cách dễ dàng:
1
2
3
4
5
from pyspark.ml.clustering import LocalLDAModel
from pyspark.ml.feature import CountVectorizer, CountVectorizerModel
countVectorizerModel = CountVectorizerModel.load(constants.OUTPUT_PATH + "/Model_CountVectorizer")
ldaModel = LocalLDAModel.load(constants.OUTPUT_PATH + "/Model_LDA")
Viết API cho ứng dụng Spark MLlib với Flask
Flask là một Web Framework rất nhẹ của Python, dễ dàng giúp người mới bắt đầu học Python có thể tạo ra website nhỏ. Flask cũng dễ mở rộng để xây dựng các ứng dụng web phức tạp. Nói chung để xây dựng một ứng dụng web nhỏ không quá cầu kì với Python thì Flask là một lựa chọn tuyệt vời.
Sau khi train mô hình và lưu lại chúng giờ đây chúng ta có thể viết một API trả về kết quả phân loại với LDA bằng Flask để có thể phân loại văn bản mới:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
from flask import Flask, request
from pyspark.ml.clustering import LocalLDAModel
from pyspark.ml.feature import CountVectorizerModel
import constants
from preprocessing import preprocessing
# init Spark Context
conf = SparkConf().setAppName("Spark ML").setMaster("local[2]")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
# init flask app
app = Flask(__name__)
@app.route("/api/predict")
def predict():
document = request.args.get("document")
countVectorizerModel = CountVectorizerModel.load(constants.OUTPUT_PATH + "/Model_CountVectorizer")
ldaModel = LocalLDAModel.load(constants.OUTPUT_PATH + "/Model_LDA")
documentDF = sqlContext.createDataFrame([(document, )], ["Content"])
rdd = documentDF.rdd
tokens = preprocessing(rdd)
tokens = tokens.zipWithIndex()
df = sqlContext.createDataFrame(tokens, ["content", "index"])
vectorizedToken = countVectorizerModel.transform(df)
result = ldaModel.transform(vectorizedToken)
result = result.select("topicDistribution")
result.show(truncate=False)
pred = result.rdd.first()
return {"predict": find_max_index(pred['topicDistribution'])}
def find_max_index(arr):
index = 0
max = 0
for i in range(0, len(arr)):
if arr[i] > max:
max = arr[i]
index = i
return index
if __name__ == "__main__":
app.run(debug=True)
- Một số hằng số
constants.OUTPUT_PATHlà các hằng số đã được khai báo trước trong fileconstants.pyđể tiện cho việc sử dụng và thay đổi một cách dễ dàng. Kết quả sau khi dự đoán sẽ là 1 mảng các xắc suất phân loại lần lượt vào các nhãn như:
1 2 3 4 5
+------------------------------------------------------------+ |topicDistribution | +------------------------------------------------------------+ |[0.15073318601831004,0.7068123476592819,0.14245446632240802]| +------------------------------------------------------------+
hàm
find_max_indexđể tìm ra nhãn nào có xắc suất cao nhất.
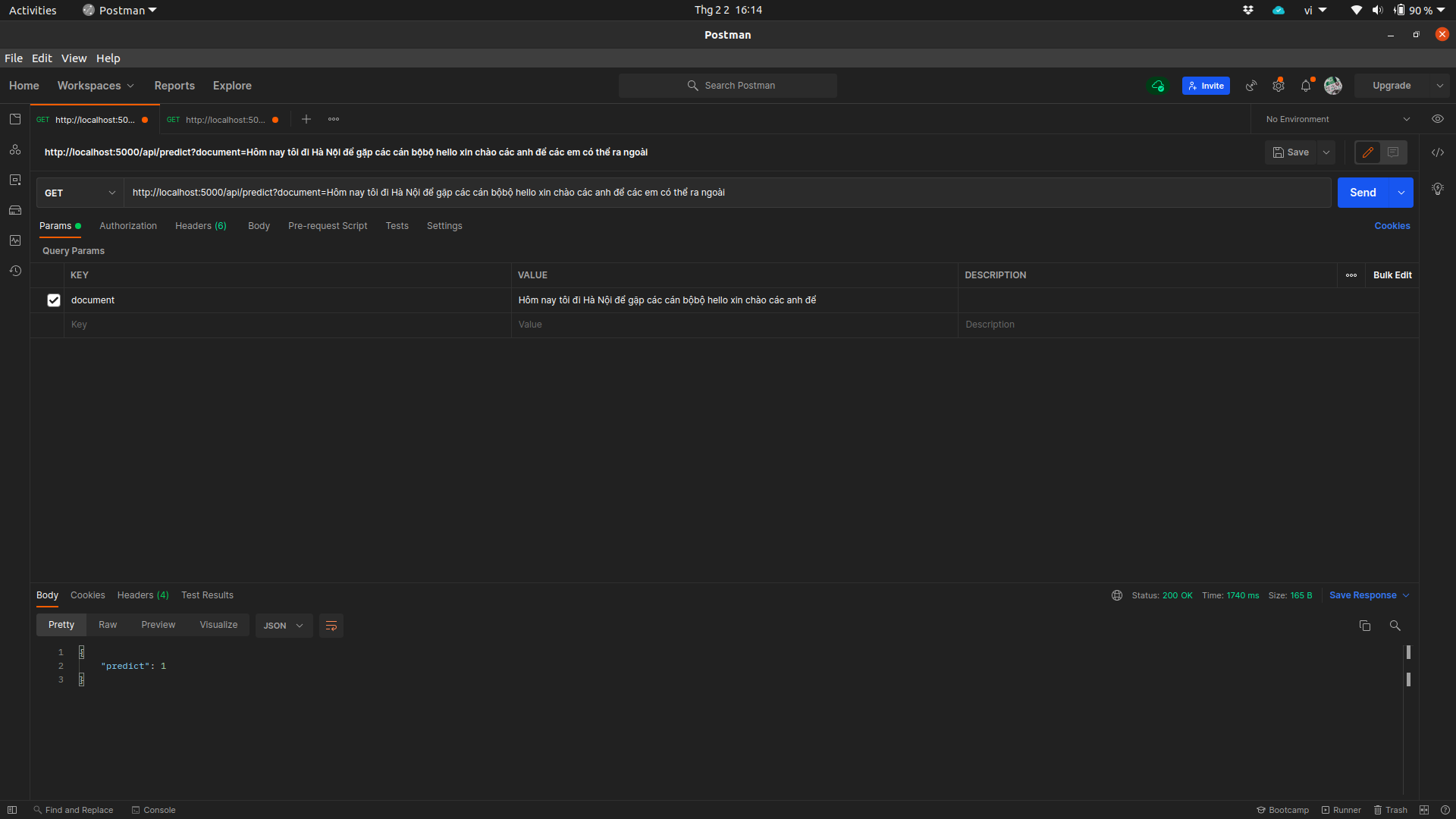
Test API với Postman
Chạy ứng dụng Flask bằng câu lệnh:
1
python3 app.py
Sau đó test thử API bằng postman sẽ thu được kết quả dự đoán:
Xem toàn bộ project trên github tại: https://github.com/demanejar/sparkml