
Hadoop Distributed File System (HDFS) is a distributed storage system designed to run on common hardware. Highly fault-tolerant HDFS is implemented using low-cost hardware. HDFS provides high-throughput access to application data so it is well suited for applications with large data sets.
Objective of HDFS
Save money on large data storage: can store megabytes to petabytes of data, in structured or unstructured form.
Data is highly reliable and capable of overcoming errors: Data stored in HDFS is duplicated into many versions and stored in different DataNodes. When one machine fails, the data is still stored. at another DataNode.
High accuracy: Data stored in HDFS is regularly checked with a checksum code calculated during the file writing process. If an error occurs, it will be restored by copies.
Scalability: can increase hundreds of nodes in a cluster.
Has high throughput: high data access processing speed.
Data Locality: process data locally.
HDFS Architecture
Follow the figure below to see an overview of the architecture of HDFS.

With HDFS, data is written on one server and can be read many times later at any other server in the HDFS cluster. HDFS includes 1 main Namenode and many Datanodes connected into a cluster.
Namenode
HDFS includes only 1 namenode called master node that performs the following tasks:
Stores metadata of actual data (name, path, block id, block location datanode configuration,…)
Manage file system namespaces (map file names to blocks, map blocks to datanodes)
Manage cluster configuration
Assign jobs to datanode
Datanode
Functions of Datanode:
Stores actual data
Directly perform and process work (read/write data)
Secondary Namenode
Secondary Namenode is a secondary node that runs together with Namenode. Looking at the name, many people mistakenly think that it is to backup Namenode, but that is not the case. Secondary Namenode is like an effective assistant of Namenode, with clear roles and tasks:
It regularly reads files and metadata stored on the datanode’s RAM and writes to the hard drive.
It continuously reads the content in Editlogs and updates it to FsImage, to prepare for the next namenode startup.
It continuously checks the accuracy of files stored on datanodes.
Heartbeat mechanism
Heartbeat is a way of communication or a way for the datanode to let the namenode know that it is alive. Periodically the datanode will send a heartbeat to the namenode to let the namenode know that the datanode is still active. If the datanode does not send a heartbeat to the namenode, the namenode considers that node to be broken and cannot perform its assigned task. Namenode will assign that task to another datanode.
Rack
In descending order from high to low, we have Rack > Node > Block. Rack is a cluster of datanodes at the same end of the network, including physical machines (equivalent to a server or node) connected to a common switch.
Blocks
Blocks are a storage unit of HDFS, data put into HDFS will be divided into blocks with fixed sizes (if not configured, the default is 128MB).
What happens if you store small files on HDFS?
Answer: HDFS is not good at handling large amounts of small files. Each data stored on HDFS is represented by 1 block with a size of 128MB, so if we store a large number of small files, we will need a large number of blocks to store them and each block we only need to use a little. and there is still a lot of space left over, causing waste. We can also see that the block size of the file system in typical operating systems like Linux is 4KB, which is very small compared to 128MB.
Work
Next, I will present the general principle of reading and writing data on HDFS:
Write data
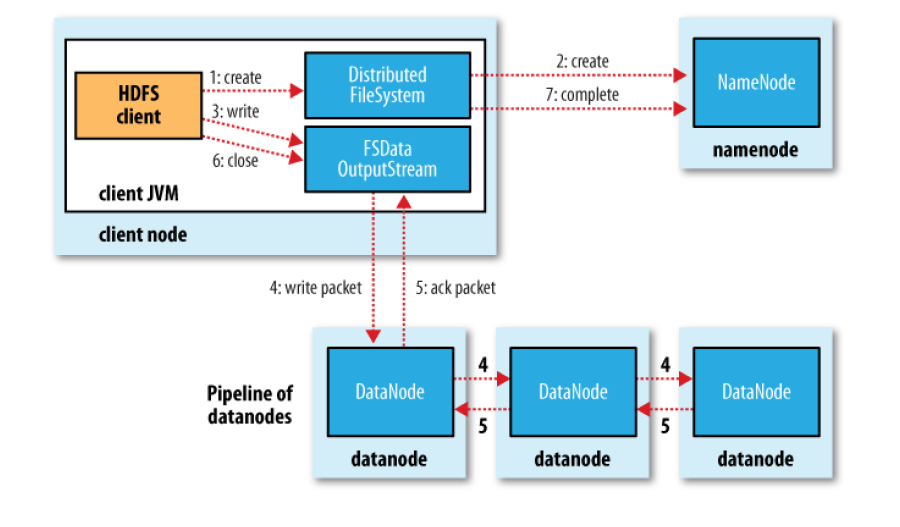
According to the sequence in the picture, we have the following steps to write data:
Client sends request to create file at DistributedFileSystem APIs.
DistributedFileSystem requires creating a file at NameNode.NameNode checks the client’s permissions and checks whether the new file exists or not…
DistributedFileSystem returns FSDataOutPutStream to the client to write data. FSDataOutputStream contains DFSOutputStream, which is used to handle interactions with NameNode and DataNode. When the client writes data, DFSOutputStream divides the data into packets and pushes it to the DataQueue queue. DataStreamer will tell NameNode to allocate blocks to datanodes to store copies.
DataNodes form the pipeline, the number of datanodes is equal to the number of copies of the file. DataStream sends the packet to the first DataNode in the pipeline, this datanode will forward the packet in turn to the Datanodes in the pipeline.
DFSOutputStream has an Ack Queue to maintain packets that have not been acknowledged by DataNodes. The packet exits the ackqueue when it receives confirmation from all DataNodes.
The client calls close() to finish writing data, the remaining packets are pushed into the pipeline.
After all packets are written to the DataNodes, the file writing completion notification is announced.
That’s all what’s going on behind the scenes, and here’s an example of one of the write operations on hdfs
1
hdfs dfs -put <path_on_your_computer> <path_on_hadoop>
In practice, we will almost never work directly with the hadoop file system (HDFS) with commands, but we often read and write through spark, for example:
1
dataFrame.write.save("<path_on_hadoop>")
Read data
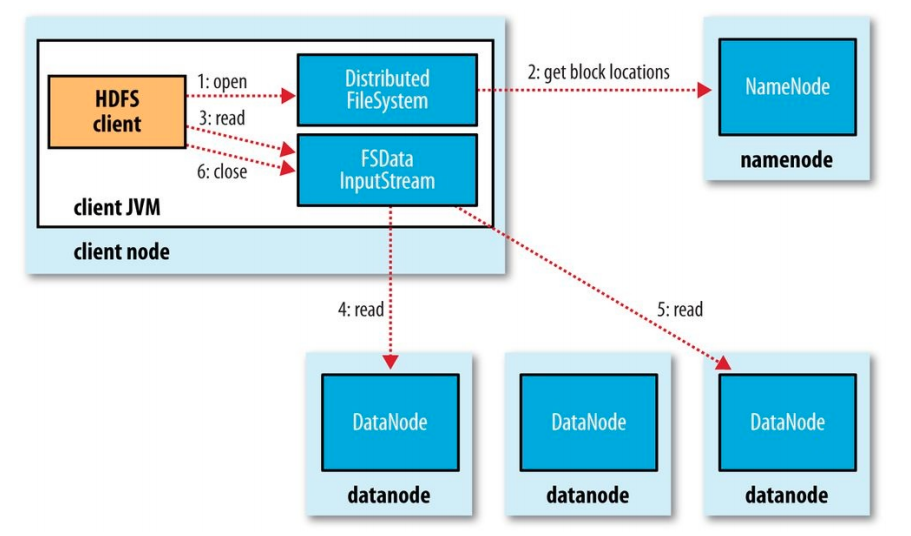
To open a file, the client calls the open method on FileSystemObject.
DistributedFileSystem calls Name to get the location of the file’s blocks. NameNode returns the address of the DataNodes containing copies of that block.
After receiving the addresses of the NameNodes, an FSDataInputStream object is returned to the client. FSDataInputStream contains DFSInputStream. DFSInputStream manages DataNode and NameNode I/O.
The client calls the read() method on FSDataInputStream, DFSInputStream connects to the nearest DataNode to read the first block of the file. The read() method is repeated many times until the end of the block.
After reading, DFSInputStream disconnects and determines the DataNode for the next block. When DFSInputStream reads the file, if an error occurs it will switch to the nearest other DataNode containing that block.
When the client finishes reading the file, call close().